
Détection des cybermenaces par vision par ordinateur (Partie 2)
Introduction
Dans notre article précédent, nous avons présenté de quelle façon la vision par ordinateur peut être utilisée pour améliorer la cybersécurité en analysant la représentation visuelle des emails et des pages web. Nous avons montré comment cette approche permet de détecter des attaques sophistiquées qu’une analyse traditionnelle du contenu pourrait manquer. Nous avons conclu en présentant un système de recherche inversée d’images chargé d’identifier les campagnes malveillantes récurrentes en comparant les captures d’écran des emails entrants avec des menaces connues.
Ce deuxième article de notre série examine plus en détail les défis techniques liés à la détection des images dupliquées et quasi-dupliquées dans le contexte de la cybersécurité. Bien que la détection de doublons d’images exacts puisse sembler simple, les attaquants introduisent souvent des variations subtiles pour échapper à la détection. Une campagne d’hameçonnage, par exemple, peut utiliser des versions légèrement modifiées du même modèle, avec des changements mineurs dans les couleurs, l’espacement ou les éléments intégrés, tout en conservant la même intention malveillante.
Pour traiter ce problème, nous examinerons, dans cet article, deux techniques fondamentales de détection de la similarité des images : les techniques basées sur le hachage et les histogrammes de couleurs. Ces méthodes constituent la base d’un système de correspondance d’images sophistiqué (d’autres méthodes plus avancées seront présentées dans le troisième article de cette série) et offrent un compromis entre précision, performance et résistance à divers types de modifications d’images.
Détection d’images dupliquées pour l’analyse des menaces
Qu’est-ce qu’une image dupliquée ?
Une image dupliquée peut être soit une copie exacte, soit une version légèrement modifiée d’une image originale. Dans les campagnes de cybersécurité, les attaquants créent souvent des variantes de la même image en la modifiant subtilement : rotation, redimensionnement, ajout de texte, ou encore application de filtres.
Bien que ces variantes soient suffisamment différentes pour contourner les filtres de sécurité, elles restent suffisamment similaires pour que les utilisateurs les reconnaissent comme étant liées. Cela crée un problème majeur : comment détecter automatiquement ces similitudes qui sont évidentes pour l’œil humain, mais complexes pour les systèmes de sécurité traditionnels ?
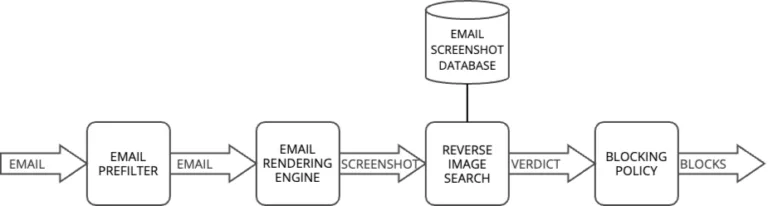
Comment fonctionne notre système de recherche inversée d’images
Notre système de recherche inversée d’images est conçu pour identifier les doublons et les variantes d’images malveillantes connues. Nous maintenons une base de données de captures d’écran d’emails malveillants connus, qui est utilisée pour analyser les emails entrants.
Lorsqu’un nouvel email arrive, le système compare son rendu visuel à cette base de données afin d’identifier les doublons potentiels ou les variantes de menaces connues. Plutôt que de classer simplement les images en tant que doublons ou non, notre système calcule un score de similarité entre 0 et 1 pour chaque paire d’images comparées.
Cette échelle continue offre un contrôle plus granulaire sur les seuils de détection, ce qui nous permet d’ajuster la sensibilité de notre système en fonction des différents scénarios de menace.
Blocage des éléments malveillants
Dès la détection d’une menace, notre politique de blocage déclenche automatiquement des mesures défensives, empêchant toute nouvelle attaque en bloquant les éléments associés tels que les adresses IP, les URL et les domaines.
Stratégie de pipeline de détection
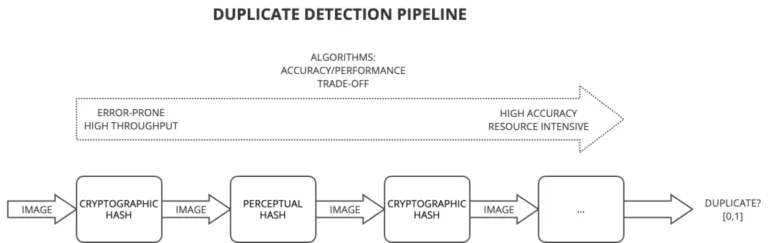
Notre pipeline de détection suit une stratégie de filtrage progressif, équilibrant vitesse et précision. Les premières couches utilisent des techniques de détection rapide qui, bien que potentiellement moins précises, peuvent traiter rapidement de grands volumes d’emails. Seuls les emails les plus suspects sont soumis à des techniques plus coûteuses en ressources. Cette approche en entonnoir optimise l’utilisation des ressources tout en maintenant une détection efficace des menaces.
Images de référence
Tout au long de cet article, nous utiliserons un ensemble d’images de référence pour démontrer chaque technique de détection, ce qui facilitera leur comparaison, en termes d’efficacité et de capacités.
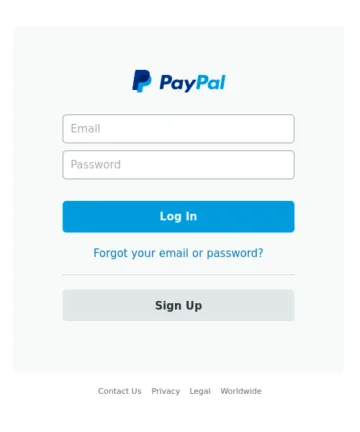
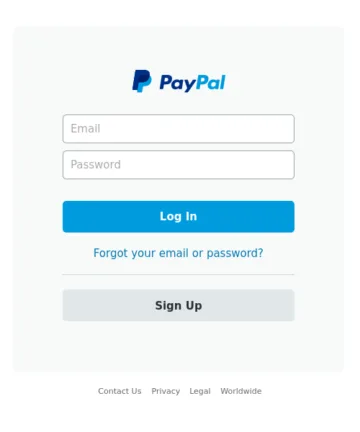
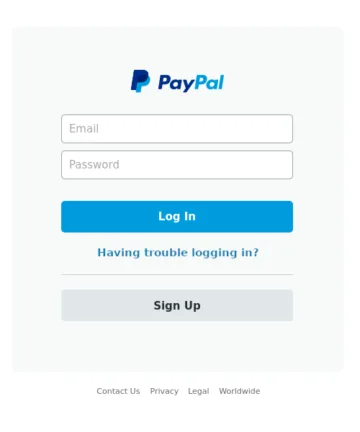
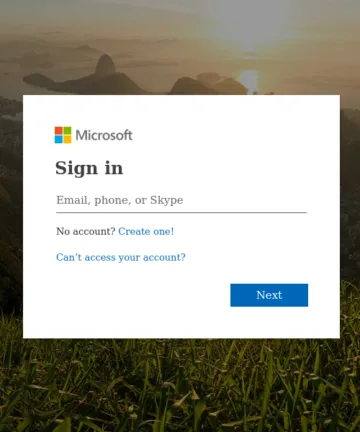
Les quatre images ci-dessus serviront d’images de référence. Parmi elles, les images A et B sont des copies identiques. L’image C est une variante avec des modifications mineures du texte dans la section de récupération du mot de passe. L’image D montre une image totalement différente.
Techniques de détection basées sur le hachage
Les techniques de détection des images dupliquées basées sur le hachage sont des algorithmes utilisés pour identifier les images dupliquées ou similaires en générant des signatures uniques, connues sous le nom de hachages ou hash, pour chaque image. Ces hashes servent de représentations compactes du contenu et des caractéristiques de l’image.
Fonctions de hachage cryptographiques
Le concept fondamental des techniques basées sur le hachage est de convertir une image en une chaîne de bits de longueur fixe (ou hash) de manière que des images similaires produisent des hashes identiques. Par conséquent, cela signifie que les doublons exacts produiront le même hash, facilitant leur identification. Les algorithmes de hachage les plus simples qui peuvent être utilisés sont des fonctions cryptographiques, telles que MD5 ou SHA-1.
Le tableau ci-dessous présente les hashes MD5 des images. Sans surprise, seules les images exactement identiques sont détectés comme des images dupliquées. Cela s’explique par le fait que les fonctions de hachage cryptographique, conçues à l’origine pour la sécurité et l’intégrité des données, sont basées sur l’effet d’avalanche : même une petite modification dans le fichier entraîne un hash considérablement différent.
| Image | Hash MD5 |
|---|---|
| A (original) | fb5e836185a7b3044e0fbb729b9e5a45 |
| B (doublon exact) | fb5e836185a7b3044e0fbb729b9e5a45 |
| C (doublon approximatif) | 0adc239afeeddab5812b9630dba97883 |
| D (différent) | 153f8ef8a277f9c11d4f18ba9ae6df6a |
Hachage perceptuel
Contrairement aux fonctions de hachage cryptographique, les techniques de hachage perceptuel offrent une approche plus souple qui tient compte des variations inhérentes aux images dues aux modifications, à la mise à l’échelle et à d’autres transformations.
Le hachage perceptuel est un type de hachage sensible à la localité (Locality Sensitive Hashing en anglais, ou LSH), une classe plus large d’algorithmes conçus pour des tâches telles que le regroupement de données et la recherche du plus proche voisin. Contrairement aux fonctionnalités de hachage traditionnelles, LSH garantit que de petites variations dans les données sources entraînent de petites variations, voire aucune variation, dans le hachage. Cette propriété rend le hachage perceptuel particulièrement adapté à l’identification d’images visuellement similaires, même lorsqu’elles ont subi des transformations mineures.
Examinons l’une des fonctions de hachage perceptuel les plus simples : Average hash.
Average hash : une méthode simple de hachage perceptuel
Average hash simplifie les images complexes en une représentation compacte tout en conservant leurs caractéristiques essentielles. Les étapes de calcul de cette technique sont les suivantes :
- Prétraitement de l’image : l’image est d’abord redimensionnée à une dimension standard (8×8 pixels, 64 pixels au total). Ce redimensionnement assure l’uniformité du traitement et minimise l’influence des petits détails.
- Conversion en niveaux de gris : l’image redimensionnée est ensuite convertie en niveaux de gris. La conversion en niveaux de gris simplifie l’image, la rend plus résistante aux variations de couleur et améliore l’efficacité de l’algorithme.
- Calcul de la valeur moyenne des pixels : la valeur moyenne de l’intensité des pixels de l’image en niveaux de gris est calculée. Cette valeur sert de référence pour déterminer si les pixels individuels sont plus sombres ou plus clairs que la moyenne.
- Génération d’un hash : l’intensité de chaque pixel est comparée à l’intensité moyenne. Si le pixel est plus clair, on lui assigne une valeur de 1 ; sinon, on lui assigne 0. Ces valeurs binaires sont concaténées en un nombre entier de 64 bits, créant ainsi un hash qui représente les caractéristiques visuelles distinctives de l’image.
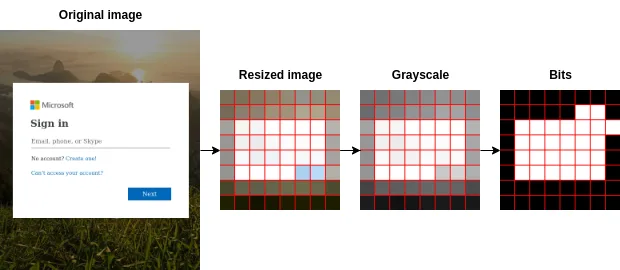
Comparaison de hashes et score de similarité
Le tableau ci-dessous présente les hashes de chacune des images à l’aide de la fonctionnalité de Average hash : le hash de l’image modifiée est presque identique à celui de l’image originale, à l’exception de deux bits.
| Image | Average hash |
|---|---|
| A (original) | ffc7ff8181c3ffff |
| B (doublon exact) | ffc7ff8181c3ffff |
| C (doublon approximatif) | ffc7ff8080c3ffff |
| D (différent) | 00067f7e7e7e0000 |
Pour comparer deux images, l’approche la plus simple consiste à utiliser la distance de Hamming sur leurs hashes respectifs. Cette distance mesure le nombre de positions où les bits sont différents entre les hashes. Par exemple, des images identiques donnent une distance de Hamming de 0. Pour manipuler les scores, un autre calcul est utilisé :
average_score(a, b) = 1 - (Hamming(a, b) / 64) Cette formule fournit une échelle entre 0 et 1, où 0 signifie que les images sont totalement dissemblables, et 1 indique que les images sont des doublons exacts. Le tableau suivant présente les distances de Hamming et les scores correspondants avec l’image originale. Par la suite, il suffit d’établir une valeur seuil au-delà de laquelle deux images sont classées comme étant des doublons.
| Image | Distance de Hamming avec l’image A | Score avec l’image A |
|---|---|---|
| B (doublon exact) | 0 | 1,000 |
| C (doublon approximatif) | 2 | 0,969 |
| D (différent) | 50 | 0,219 |
Limites du hachage perceptuel
Bien qu’ils soient efficaces pour détecter les doublons exacts ou approximatifs, les hachages perceptuels peuvent avoir des difficultés avec les images modifiées, avec des transformations telles que la rotation ou la mise à l’échelle.
En outre, les méthodes de hachage perceptuel peuvent parfois produire des faux positifs ou négatifs, ce qui a un impact sur la précision, surtout lorsqu’il s’agit d’images qui partagent des éléments visuels similaires, mais dont le contenu sémantique est différent. Par exemple, Hao et al. ont proposé dans « It’s Not What It Looks Like : Manipulating Perceptual Hashing based Applications », une série d’algorithmes d’attaque visant à manipuler les techniques de hachage perceptuel.
Pour remédier à ces limitations, le hachage perceptuel est souvent combiné à des techniques basées sur le contenu, telles que les histogrammes de couleurs, présentés dans la section suivante.
Histogrammes de couleurs
Une limitation inhérente à la technique Average hash présentée précédemment est qu’elle ne tient pas compte de la couleur de l’image en raison de son approche en niveaux de gris. Par conséquent, une piste prometteuse pour améliorer notre système consiste à mettre en œuvre une technique basée exclusivement sur les couleurs, en utilisant des histogrammes de couleurs.
Cette approche consiste à capturer la distribution des couleurs présentes dans une image et à la représenter sous forme d’histogramme. En quantifiant l’occurrence de chaque couleur dans l’image, la technique de l’histogramme des couleurs offre un outil puissant pour identifier les images présentant des modèles de couleurs similaires.
Calcul d’un histogramme
Le calcul d’un histogramme de couleurs à partir d’une image comporte plusieurs étapes :
- Préparation de l’image : convertir l’image dans un espace de couleurs RGB approprié et la redimensionner pour des raisons de performance.
- Échantillonnage (ou quantization) : réduire le nombre de couleurs distinctes dans l’image tout en conservant sa qualité visuelle globale. Cela nous permet d’économiser de la mémoire et de réduire la complexité des calculs. Nous utilisons une palette réduite de 16 couleurs, conçue pour plusieurs tâches.
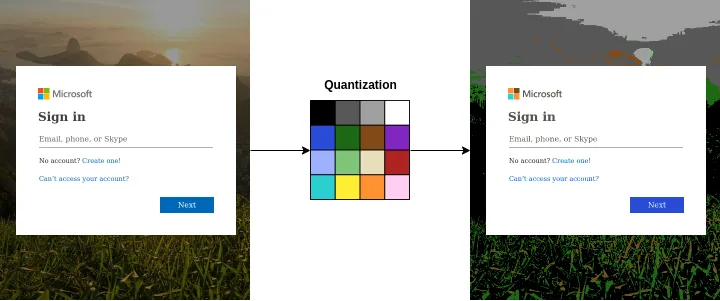
- Décompte des pixels : compter le nombre de pixels qui se trouvent dans chacun des 16 groupes de couleurs.
- Normalisation : pour que les histogrammes soient indépendants de la taille de l’image, nous normalisons les valeurs en divisant le nombre de pixels de chaque couleur par le nombre total de pixels de l’image.
Pour faciliter la compréhension de cette technique, la figure ci-dessous représente les histogrammes de couleurs de nos quatre images de référence, ne présentant que quatre des seize couleurs pour des raisons de lisibilité.
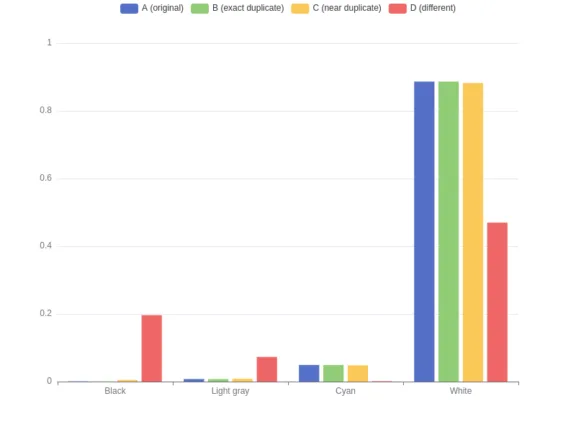
Comparaison d’histogrammes et score de similarité
Comme pour les techniques de hachages, nous calculons les distances entre les histogrammes de couleurs à l’aide de la distance de Manhattan (également appelée distance L1) qui consiste à calculer la somme des différences absolues entre les valeurs des histogrammes. Lorsque l’on utilise cette distance pour comparer des images, des distributions de couleurs similaires donneront des distances plus faibles. Deux copies donneront une distance L1 de 0. Dans le cas extrême opposé, où deux histogrammes sont complètement différents, la distance L1 est de 2 (la somme des deux histogrammes normalisés). Comme nous l’avons fait précédemment pour Average hash, nous préférons un calcul alternatif.
L1_dist(a, b) = abs(a[0] - b[0]) + abs(a[1] - b[1]) + ... + abs(a[15] - b[15])
hist_score(a, b) = 1 – L1_dist(a, b) / 2 Cette formule fournit une échelle entre 0 et 1, où 0 signifie une distribution des couleurs de l’image totalement différente, et 1 indique une distribution des couleurs exactement identique. Le tableau suivant présente les scores de similarité et la distance L1 avec l’image originale.
| Image | Distance L1 avec l’image A | Score avec l’image A |
|---|---|---|
| B (doublon exact) | 0,000 | 1,000 |
| C (doublon approximatif) | 0,011 | 0,994 |
| D (différent) | 1,024 | 0,488 |
Limitations des histogrammes de couleurs
Cette approche présente une limitation évidente : elle n’examine que la distribution des couleurs dans les images, sans tenir compte de leur emplacement. De plus, il faut faire attention à la taille de la palette réduite de couleurs, qui pourrait avoir un impact sur les résultats. Si les techniques abordées jusqu’à présent (notamment le hachage perceptuel et les histogrammes de couleurs) peuvent indiquer des ressemblances entre les images, il est crucial de vérifier si les objets représentés sont réellement similaires. Cet aspect fera l’objet du prochain article.

Conclusion
Dans cet article, nous avons présenté deux techniques fondamentales pour détecter les images dupliquées et quasi dupliquées : les méthodes basées sur le hachage et les histogrammes de couleurs. Bien que ces approches offrent des capacités de filtrage initial efficaces, elles ont chacune leurs limites. Le hachage perceptuel peut être vulnérable à des altérations spécifiques, et les histogrammes de couleurs, bien qu’utiles pour analyser les distributions de couleurs, ne prennent pas en compte la disposition spatiale des éléments visuels.
Ces techniques servent de mécanismes de sélection rapide dans notre pipeline de détection, offrant un bon équilibre entre l’efficacité des calculs et la précision de détection. Cependant, pour les décisions de sécurité à fort enjeu, nous avons besoin de méthodes plus sophistiquées pour vérifier que les similitudes détectées indiquent réellement des menaces dupliquées.
Dans notre prochain article, nous présenterons les approches basées sur le contenu des images, qui analysent les éléments visuels et leurs relations au sein des images. Ces méthodes, bien que plus coûteuses en ressources, offrent la grande précision nécessaire à une détection fiable des doublons. Nous verrons comment ces techniques peuvent nous aider à identifier avec certitude les variantes de menaces connues, même lorsque les attaquants utilisent des techniques de modification sophistiquées pour échapper à la détection.

