
Détection des cybermenaces par vision par ordinateur (Partie 1)
Introduction
Bienvenue dans le premier article d’une série de quatre sur le thème de la détection des cybermenaces à l’aide de la Computer Vision (vision par ordinateur).
Pour le contexte : Hornetsecurity utilise des méthodes de Computer Vision dans ses services de détection de phishing, tels que ATP Secure Links, pour détecter des modèles visuels dans les tentatives de phishing.
Dans les prochains articles, nous nous concentrerons sur le « comment » et nous présenterons différentes techniques et algorithmes de Computer Vision qui peuvent être utilisés et combinés à cette fin.
Aujourd’hui, les deux principaux vecteurs de cybermenaces sont les emails et les liens :
- Les emails sont omniprésents dans la communication d’entreprise, que ce soit pour la communication interne des équipes ou les échanges externes avec des clients ou partenaires.
- Les liens sont également largement partagés, que ce soit par courrier électronique, mais également via d’autres types de messagerie – outils collaboratifs d’entreprise comme Teams et Slack, SMS ou messagerie instantanée (WhatsApp, WeChat, etc.).
Lorsqu’ils sont présentés à l’utilisateur final, l’email et la page Web associés au lien sont restitués graphiquement à l’utilisateur final, respectivement par le logiciel de messagerie et le navigateur Web. Le moteur de rendu du logiciel de messagerie ou du navigateur Web analyse d’abord le document HTML, puis charge les ressources (images, fichiers CSS, JS, etc.) nécessaires et enfin le transforme en une représentation visuelle sur l’appareil de l’utilisateur final. Ce qui est présenté à l’utilisateur final n’est pas le code source du document HTML, mais sa transformation en représentation visuelle par le logiciel de messagerie ou le navigateur web.
Les technologies web (HTML, CSS, JS) sont devenues de plus en plus sophistiquées au fil du temps. Cela a permis aux cybercriminels de concevoir des techniques pour échapper aux solutions de sécurité telles que les filtres email et les scanners web qui s’appuient sur l’analyse du contenu plutôt que sur sa représentation visuelle. Ces techniques peuvent être utilisées pour dissimuler du contenu malveillant ou des indices d’une attaque, ou encore pour perturber l’analyse effectuée par les couches de sécurité.
Les techniques utilisées par les attaquants pour échapper aux filtres traditionnels
Parmi les nombreuses techniques employées par les cybercriminels, nous nous concentrerons sur deux approches particulièrement sophistiquées qui posent des défis importants aux mesures de sécurité traditionnelles.
Phishing basé sur le QR Code
La capture d’écran de l’email suivant présente une tentative de phishing reposant sur un code QR et usurpant l’identité de DHL. Le code QR a été partiellement expurgé pour des raisons de sécurité.

L’utilisation de codes QR pour mener des attaques de phishing – également connues sous le nom de Quishing – est désormais habituelle car les utilisateurs finaux ont l’habitude de scanner ces codes à l’aide de leur smartphone. Pour l’attaquant, les codes QR constituent également un moyen très efficace d’échapper à de nombreuses solutions de sécurité existantes car l’extraction du lien sous-jacent nécessite l’application de techniques coûteuses de Computer Vision (vision par ordinateur).
Les codes QR sont généralement des images jointes à l’email ou référencées dans une balise d’image HTML. Ce n’est toutefois pas le cas dans cet exemple. Ici, le code QR résulte de l’affichage de l’email : le code QR est en effet formé dans le code source HTML par la concaténation de caractères en forme de blocs dans une structure de tableau. Un zoom sur le code QR met en évidence la disposition de ces caractères, et ceux-ci peuvent être sélectionnés individuellement dans le client de messagerie, comme illustré ci-dessous.

Du point de vue de la protection, l’extraction du lien malveillant nécessiterait un affichage complet de l’email, et pas seulement le traitement des images jointes ou référencées dans le code source. Cette technique consistant à exploiter les tableaux HTML pour générer du contenu visuel à la volée a également été utilisée pour usurper l’identité de marques, les pixels du logo étant générés à l’aide de blocs de couleur. Cette technique a été notamment utilisée pour usurper l’identité de Microsoft et de Chase, comme le montre la capture d’écran ci-dessous.
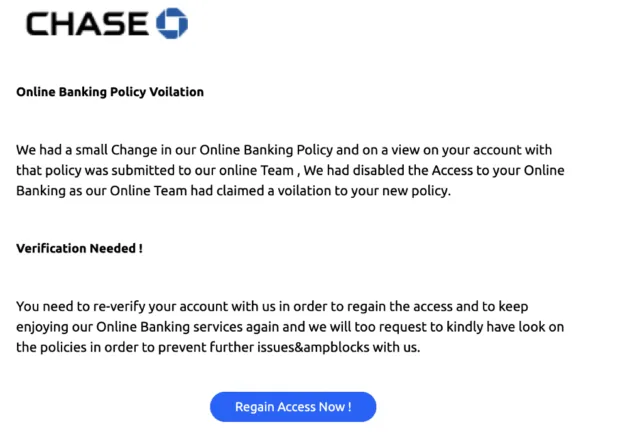
Si nous zoomons sur le logo Chase, nous pouvons voir qu’il est formé d’une agrégation de blocs de couleur bleue dans un tableau HTML.

Phishing ZeroFont
Une autre technique utilisée pour dissimuler des éléments malveillants et échapper aux filtres de sécurité est connue sous le nom de technique « ZeroFont ». La technique ZeroFont fait partie d’une famille plus large de techniques qui exploitent les caractéristiques de HTML et CSS pour insérer du texte qui n’est pas visible par l’utilisateur final : il peut s’agir d’un texte dont la couleur est identique ou proche de la couleur d’arrière-plan – ou de masquer un élément avec la propriété de visibilité CSS.
Comme son nom l’indique, la technique ZeroFont est basée sur l’insertion de texte dont la taille de la police est fixée à zéro, et donc le texte n’est pas affiché et visible pour l’utilisateur final. Comme les langages HTML et CSS sont complexes, il existe de nombreuses façons d’y parvenir. La plus simple consiste à fixer la taille de la police à zéro pixel. Comme elle peut être détectée par les solutions défensives, les attaquants ont développé de nombreuses variantes en tirant parti de la complexité des propriétés CSS (unité de longueur relative, styles, etc.), ou en fixant la taille de la police à une valeur proche de zéro.
Voici un exemple de la technique ZeroFont utilisée dans un email frauduleux usurpant l’identité de Geek Squad, une société bien connue qui fournit une assistance technique aux clients de Best Buy. Dans cette escroquerie, l’objectif de l’attaquant est que l’utilisateur final ciblé appelle un numéro de téléphone gratuit frauduleux.

Une analyse du code source HTML révèle que le numéro de téléphone frauduleux est obscurci d’une manière alambiquée, comme illustré ci-dessous. Des éléments HTML de taille zéro (voir ‘style=”font-size:0vw”’) sont insérés entre les séquences de chiffres et de traits d’union (« 88 », « 8-« , « 72 », « 9-« , « 12 » et « 52 »), ce qui rend l’extraction du numéro de téléphone extrêmement difficile pour un filtre email traditionnel.

Comment la Computer Vision peut-elle être utile ?
Ces techniques soulignent la nécessité de tirer parti de la Computer Vision pour extraire correctement le signal du bruit et analyser un email ou une page web comme le ferait un être humain. Il s’agit toutefois d’un défi car la Computer Vision est coûteuse en termes de ressources. En outre, il est nécessaire d’afficher l’email ou la page web au préalable, une opération qui peut prendre plusieurs secondes dans le cas où des ressources distantes (images, CSS, fichiers JS) doivent être téléchargées pour effectuer un rendu graphique correct et fidèle.
Email rendering pour analyser les e-mails suspects
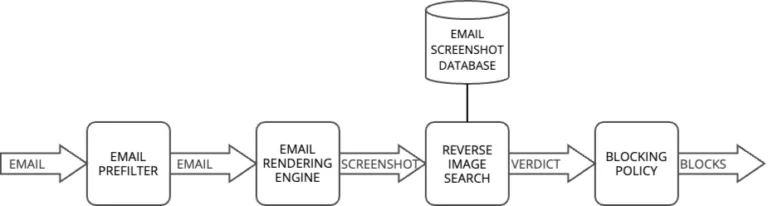
En pratique, dans le contexte des emails, l’application d’un moteur d’affichage d’emails suivie d’une analyse par Computer Vision ne peut être effectuée que sur un échantillon du trafic d’emails considéré – seuls les emails les plus suspects devraient être candidats. Un exemple de pipeline est proposé dans le diagramme suivant.

- Tout d’abord, le flux email est préfiltré. De nombreux éléments peuvent être pris en compte pour déterminer si un email est suspect – il peut s’agir, par exemple, du fait que l’adresse email de l’expéditeur est inconnue. Si l’email est suspect, un rendu graphique est effectué par le moteur d’affichage. Il existe de nombreuses bibliothèques et logiciels pour effectuer l’affichage – chromedp est une option populaire.
- L’affichage graphique – ou « capture d’écran » – est ensuite analysé par le moteur de Computer Vision. Les capacités du moteur dépendent des fonctionnalités mises en œuvre : la reconnaissance optique de caractères (OCR) pourrait être utilisée pour extraire du texte (comme le numéro de téléphone gratuit dans l’email d’escroquerie de Geek Squad), et un lecteur de codes-barres pourrait extraire des liens de codes QR (comme le lien malveillant dans l’email d’hameçonnage de DHL).
- Ces caractéristiques sont ensuite transmises à un moteur de décision qui les combine et rend un verdict.
- Enfin, en fonction du verdict, des éléments seront bloqués conformément à une politique de blocage, afin d’empêcher de nouvelles attaques. Différents éléments peuvent être bloqués, tels que l’adresse email de l’expéditeur, le domaine de messagerie, l’adresse IP d’envoi et la plage d’adresses IP. Dans le cas d’un lien malveillant, l’URL et le domaine peuvent être bloqués.
Recherche d’images inversée pour détecter le contenu malveillant
Une autre approche possible consisterait à remplacer le moteur de Computer Vision et le moteur de décision par un composant de recherche inversée d’images couplé à une base de données de captures d’écran d’emails.
Pourquoi cette approche particulière ?
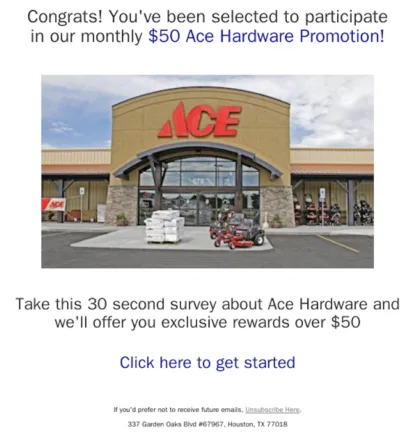
Parce que les analystes d’Hornetsecurity sont confrontés à des campagnes de spam d’affiliation sophistiquées et récurrentes qui usurpent l’identité de marques de grande distribution bien connues (Costco, Lowes, Walmart, Ace Hardware, etc.). L’un des principaux défis est que le contenu de l’email est extrêmement variable d’un email à l’autre – les spammeurs connaissent toutes les astuces pour ajouter des éléments parasites et cacher le contenu pertinent – alors que la représentation visuelle de l’email n’évolue pas beaucoup dans le temps – mais elle change.
Exemples de contenu variable dans un email
Deux exemples de ces emails sont présentés ci-dessous, où l’utilisateur final est invité à cliquer sur un lien indésirable. Bien que les emails soient similaires, ils présentent quelques différences. La plus évidente est le changement de couleur du texte, d’abord rouge puis bleu. D’autres changements sont toutefois plus subtils : la taille relative de l’image, l’espacement entre les différents blocs.

Comment détecter
Pour détecter ce type de spam récurrent, les analystes pourraient alimenter une base de données de captures d’écran de « spam » connues, puis, chaque fois qu’un email suspect est analysé, le composant de recherche inversée d’images interroge la base de données pour savoir si la capture d’écran de l’email est connue comme étant du « spam ». Si c’est le cas, les éléments sont bloqués pour arrêter la campagne.
Le composant de recherche inversée d’images doit être capable d’effectuer une « recherche floue » – en d’autres termes, il doit pouvoir être résilient à de petites différences dans le rendu graphique. Le même principe peut être utilisé pour détecter d’autres emails malveillants récurrents tels que le phishing – dans ce cas, des variantes de la campagne de phishing peuvent être détectées, comme un email de phishing avec un code QR différent.

Conclusion
Dans les prochains articles, nous nous pencherons sur les algorithmes qui peuvent être utilisés pour mettre en œuvre un moteur de recherche inversée d’images. Ce problème – également connu sous le nom de détection d’images en double ou de détection d’images en quasi-double – a été largement étudié par les universitaires, et nous nous référerons à la littérature académique existante.

