
Unraveling RTO vs. RPO: Key Factors in Disaster Preparedness
With sufficient funding and infrastructure, any system could theoretically achieve near-constant uptime through any situation. Reality dictates a more conservative outlook. To establish a workable budget and a practical plan, you will need to determine your organizational tolerances for outages and loss. This article explores the related terminology and processes.
Now, you will need to have the key employees of each system explore the question more deeply. If the term “business impact” does not convey the desired level of urgency, ask questions such as
“How much does this system cost us per hour when offline?” and
“How many hours of work would we need to recover after losing one hour’s worth of data?”
Establishing Recovery Time Objectives
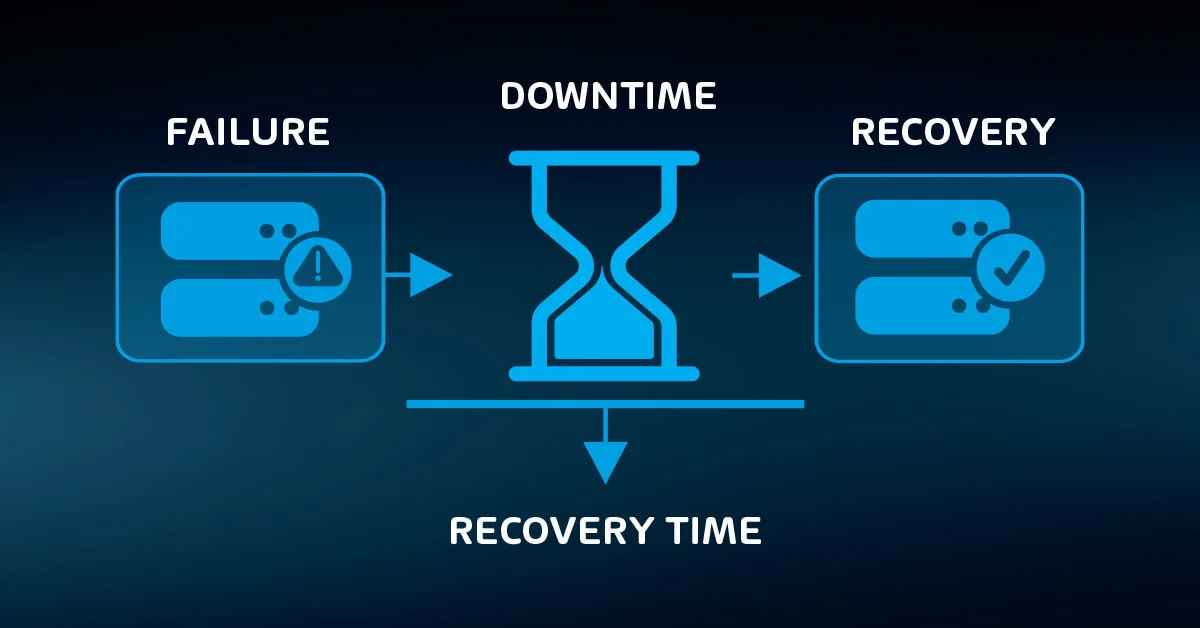
The simple question, “How long can we operate without this system?” can get your teams started. The term “recovery time objective” (RTO) applies to the goals set by this enquiry. RTOs establish the desired maximum amount of time before a system returns to a defined usable state.
Complex systems can have different RTOs. For instance, you might set an RTO of four hours to restore a core electronic records system after a major failure but set a separate objective of one hour after a minor glitch. Your objectives might also set differing levels for acceptable functionality.
Your organization might consider a functioning receipt printer in the customer service area as a meaningful success metric; it can have its own RTO as a part of a larger recovery objective.
RTOs should feature prominently in your long-term disaster recovery planning. Rely on the managers and operators of the individual systems to provide guidance. Use executives to resolve conflicting priorities. You may also need them to grant you the ability to override decisions in order to ensure proper restoration of functionality.
Establishing Recovery Point Objectives
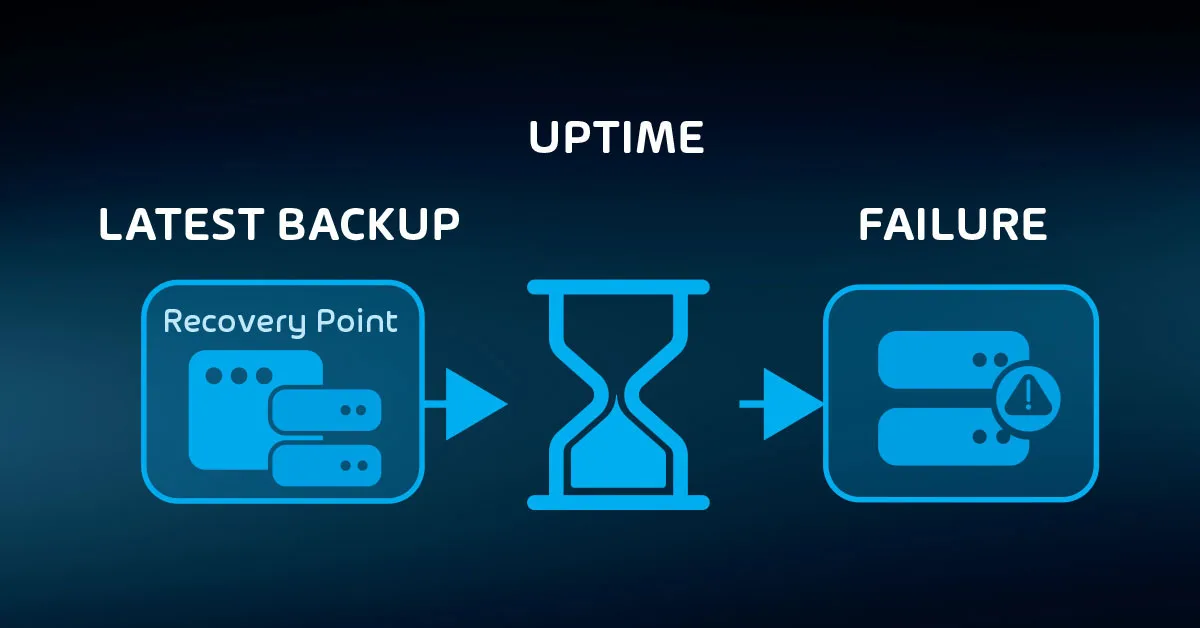
RTOs apply mainly to functionality. Events that trigger recovery actions also tend to cause data loss. Your organization will need to establish tolerance. Of course, no one wants to lose anything, which will make these discussions difficult.
Because most backups occur at specific time intervals, you use them as the basis for “recovery point objectives” (RPO). An RPO sets the maximum acceptable time span between the latest backup and the data loss event.
This determination coincides with the work to determine the business impact of an outage. A system’s downtime not only prevents its users from retrieving or utilizing its contents but also requires post-recovery work: staff will need to recreate any data that was not in the backup and complete postponed operations.
You will need to establish multiple RPOs for most systems. Not all events will have the same impact, so you must set expectations accordingly. For instance, you have options for continuously created replicas and backups.
Those work well as buffers against physical hardware failure. They work poorly against malicious attacks, especially encrypting ransomware.
You can establish a tiered recovery approach to address the various risks. As an example:
- First-line hardware failure or malfunction: RPO of zero hours, using continuous replication
- Corrupted data: RPO of 1 hour after corruption detection, using on-site hourly backups
- Site destruction: RPO of 24 hours, using off-site daily backups and cloud hosting providers
Consider the possible outcomes of each risk category as you work out RPOs. You don’t just need the data to restore; you need something to restore it to.
If you need to acquire replacement hardware or bring in third parties for assistance, that might add time. If you have a secondary site available, add an RPO item for recovery to that location. Also include an item that addresses cross-facility challenges. Do not forget to account for the availability of critical staff.
Defining Retention Policies
Your teams have a final major decision to make: how long to keep data. These decisions are highly dependent on the nature of the business and the data. For European-based operations you may also have to consider GDPR requirements. If you don’t have immediate answers, use two major guidelines:
- Legal requirements. As an example, you may need to keep records of taxable events for a number of years.
- How long will the data have value?
Ensure that the burden of answering these questions does not fall solely to IT. Because it involves the word “data”, some will see a natural responsibility for technology staff to take ownership. However, IT typically does not hire legal experts, and corporate liability tends to fall on the shoulders of executives.
As to the second point, tech departments may have some business knowledge, but “value” often means a subjective assessment that should, at the very least, involve the data owner.
Use the answers from these questions to create “retention policies”. A retention policy dictates how long data must be retrievable. You will likely need more than a single company-wide policy. “Forever” may seem like an obvious answer for some things but ensure that everyone understands that data storage has an associated cost.
Data retention has two tiers:
- live storage
- backup storage
In disaster recovery planning, IT often only considers the backup tier. However, remember that a backup captures existing data, regardless of its age. So, if a live database has records that go back a decade, then the most recent backup contains ten-year-old information.
Therefore, both your current live data and yesterday’s backup satisfy a ten-year retention policy.

To accommodate both the live and the backup tiers, retention policies must consider two things:
- Purge policies for active data
- Probability of unnoticed undesired deletion
Some electronic records systems prevent true deletion from databases without a purge action. It might move “deleted” records into a historical table or it may have a flag that removes them from visibility in client applications. Such safeguards reduce the probability of accidents.
They can help against malicious deletion as well. Remember that individuals with administrative access can usually override application-level security. For the greatest safety, assume that you will not achieve your retention policies for live data.
You can relax that expectation for non-critical data. Factor in the results of impact analysis from the earlier exercises.
Ask, “If we lost this data forever, how would it impact the organization?”
Adjusting RTOs, RPOs, and Retention Policies to Match Practical Restraints
Shorter RTOs and RPOs almost always require greater financial and technical resources. Short backup intervals consume more media space and network bandwidth. Lengthy retention policies increase storage and administrative costs. Layered approaches to cover the various risk profiles can multiply those needs.

Backup operations place a load on the production system, which might add more strain than your current equipment allows. Replication and continuous backup technologies need more technical expertise than typical nightly backups. Staff must periodically test the validity of backup data, adding effort and overhead.
Make all these constraints clear during early planning meetings. As executives and department heads express their wishes for speedy RTOs and short RPOs, ensure that they understand that costs will rise accordingly. They may need to adjust their expectations to match.
Your plans also need to factor in time and expense to re-establish infrastructure after a failure. You may need to replace physical systems. Vital foundational infrastructure, such as domain controllers, automatically take precedence over anything that depends on them. Adjust RTOs and RPOs for dependent systems accordingly.
The backup software that you choose will play a role in your RTO and RPO restrictions. Hornetsecurity’s VM Backup V9 provides highly customizable backup scheduling options as well as Continuous Data Protection (CDP). You need fine-grained flexibility such as this to balance your backup needs against your available resources.
Reviewing Recovery Objectives
The major activities of this article include input from all sectors of the business. Through interviews, questionnaires, and meetings, you can assemble an organizational view of what you need to protect. Next, you need to determine how you will implement that protection.
You have not completely finished working with the non-technical departments, but you can allow them to gather the necessary data while you move to a different phase of the project.
To properly protect your virtualization environment and all the data, use Hornetsecurity VM Backup to securely back up and replicate your virtual machine.
For complete guidance, get our comprehensive Backup Bible, which serves as your indispensable resource containing invaluable information on backup and disaster recovery.
To keep up to date with the latest articles and practices, pay a visit to our Hornetsecurity blog now.

Conclusion
In conclusion, understanding the crucial distinctions between RTO (Recovery Time Objective) and RPO (Recovery Point Objective) is fundamental to disaster preparedness. While achieving constant uptime is ideal, practicality and budget constraints necessitate a balanced approach.
By clearly defining your organization’s tolerance for outages and data loss, you can develop a resilient disaster recovery strategy that aligns with your resources and objectives. Carefully considering RTO and RPO will empower your business to navigate unforeseen challenges more confidently and efficiently.
FAQ
What is the difference between RTO and RPO?
RTO (Recovery Time Objective) refers to the maximum acceptable downtime for a system or application after a disruption occurs. It represents the time it takes to fully restore functionality to a level that allows normal operations to resume. In layman’s terms, RTO answers the question, “How quickly do we need our systems back online?”
RPO (Recovery Point Objective) defines the maximum allowable data loss after a disruption. It represents the point in time to which data must be recovered to ensure minimal business impact. In essence, RPO answers the question, “How much data are we willing to lose in a disaster?”
Moreover, RTO is your organization’s goal for the maximum time it should take to restore normal operations following an outage or data loss while RPO is your goal for the maximum amount of data the organization can tolerate losing.
What are RTO and RPO examples?
They are strictly numeric time values. For example, an RTO for a reasonably critical server might be one hour, whereas the RPO for less-than-critical data transaction files might be 24 hours and might also support the use of backup tape storage equipment.
RTO Example
Suppose a financial institution sets an RTO of 4 hours for its online banking system. In the event of a system failure or disaster, they must restore full functionality within 4 hours to meet their RTO.
RPO Example
A hospital establishes an RPO of 1 hour for its electronic health records system. This means that even in the event of a failure, they cannot afford to lose more than 1 hour’s worth of patient data.
Which is more important RTO and RPO?
RPO designates the variable amount of data that will be lost or will have to be re-entered during network downtime. RTO designates the amount of “real-time” that can pass before the disruption seriously and unacceptably impedes the flow of normal business operations.
RTO Importance
RTO is often more critical for systems and applications where downtime can have immediate and severe consequences. Industries such as finance or e-commerce may prioritize minimizing downtime to ensure continuous operations.
RPO Importance
RPO is crucial when data integrity and compliance are paramount. Organizations dealing with sensitive information, like healthcare or legal firms, may prioritize minimizing data loss to ensure accuracy and legal compliance.
