
Detection of Cyberthreats with Computer Vision (Part 1)
Introduction
Welcome to the first article of our four-part series on the topic of the detection of cyberthreats with Computer Vision. In this article, we will explain why Computer Vision can help to detect cyberthreats.
For context: Hornetsecurity utilizes Computer Vision methods in its phishing detection services, such as ATP Secure Links, to detect visual patterns in phishing attempts.
In the next articles, we will focus on the ‘how’, and we will present different Computer Vision techniques and algorithms that can be used and combined for this purpose.
Nowadays, the two main vectors of cyberthreats are emails and links:
- Emails are ubiquitous in business communication, whether for internal team communication or external exchanges with customers or partners.
- Links are also widely shared, whether via email, but also through other types of messaging – enterprise collaborative tools such as Teams and Slack, text message or instant messaging (WhatsApp, WeChat, etc.).
When presented to the end user, the email and webpage associated to the link are rendered graphically to the end user, by the email software and the web browser respectively. The rendering engine of the email software or web browser first analyses the HTML document, then loads the resources (Images, CSS, JS files, etc.) required, and at last transforms it into a visual representation on the end user device. What is presented to the end user is not the source code of the HTML document, but its transformation into a visual representation by the email software or web browser.
Web technologies (HTML, CSS, JS) have become increasingly sophisticated over time. This has allowed cybercriminals to devise techniques to evade security layers such as email filters and web scanners that rely on content analysis rather than on its visual representation. These techniques can be used to conceal malicious content or clues of an attack, or alternatively to disrupt the analysis performed by the security layers.
Techniques used by attackers to evade traditional filters
Among the numerous techniques employed by cybercriminal, we will focus on two particularly sophisticated approaches that pose significant challenges for traditional security measures.
QR code based phishing
The following email screenshot presents a QR code based phishing attempt impersonating DHL. The QR code has been partially redacted for security reasons.

The use of QR codes to carry out phishing attacks – also known as Quishing – is now customary, as end users are used to scanning these codes with their smartphone. For the attacker, QR codes are also a very efficient way to evade many existing security layers, as the extraction of the underlying link requires to apply costly Computer Vision techniques.
QR codes are typically images that are either attached to the email or referenced in an HTML image tag. However, this is not the case in this example. Here, the QR code results from the rendering of the email: the QR code is indeed formed within the HTML source code by the concatenation of blocky characters in a table structure. A zoom on the QR code highlights the arrangement of these characters, and these characters can be selected individually in the email client, as shown below.

From a defense perspective, extracting the malicious link would require to fully render the email, not just process the images attached or referenced in the source code. This technique of leveraging HTML tables to generate visual content on the fly has also been used to impersonate brands as the pixels of the logo are generated with colored blocks. This technique has been used to impersonate Microsoft, as well as Chase, as shown below.
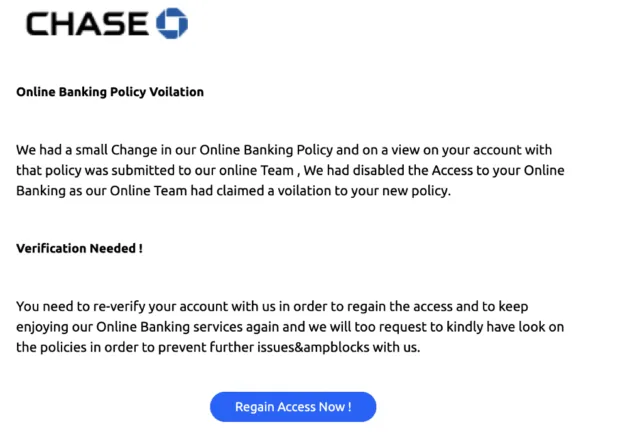
If we zoom on to the Chase logo, we can see that it is formed by an aggregation of blue colored blocks within an HTML table.

ZeroFont phishing
The ZeroFont technique is used to hide malicious elements and evade security filters. This technique is part of a broader family of techniques that leverage features of HTML and CSS to insert text that is not visible to the end user: it can be a text whose color is identical or close to the background color – or hiding an element with the CSS visibility property.
As its name suggests, the ZeroFont technique is based on the insertion of text where the font size is set to zero, and thus the text is not rendered and visible to the end user. As HTML and CSS are complex, there are many ways to achieve this. The most straightforward way is to set the font size property to zero pixels. As it can be detected by defensive layers, attackers have developed many variants by leveraging the complexity of CSS properties (Relative length unit, styles, etc.), or setting the font size to a value close to zero.
Here is an example of ZeroFont technique used in an email scam impersonating Geek Squad, a well-known company providing technical support and assistance to Best Buy customers. In this scam, the goal of the attacker is that the targeted end user calls a fraudulent toll-free phone number.

An analysis of the HTML source code reveals that the fraudulent phone number is obfuscated in a convoluted way, as illustrated below. HTML span elements of size zero (See ‘style=”font-size:0vw”’) are inserted between the sequences of digits and hyphens (‘88’, ‘8-’, ‘72’, ‘9-’, ‘12’ and ‘52’) making the extraction of the phone number extremely difficult for a traditional email filter.

How can Computer Vision be useful?
These techniques highlight the need to leverage Computer Vision to extract correctly the signal from noise and analyse an email or a webpage like a human would do. This is, however, challenging as Computer Vision is costly in terms of resources. Furthermore, it is necessary to render the email or webpage beforehand, an operation that can take several seconds in the case resources (Images, CSS, JS files) need to be fetched from the internet to perform a correct and faithful graphical rendering.
Email rendering to analyse suspicious emails
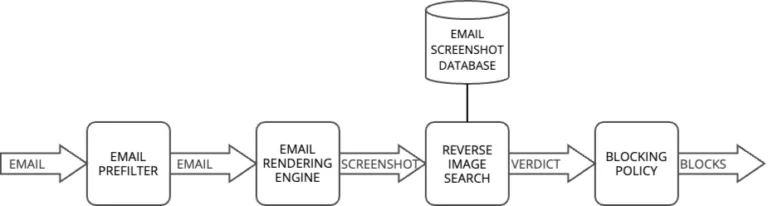
In practice, in the context of email, the application of an email rendering engine followed by a Computer Vision analysis can only be performed on a sample of the considered email traffic – only the most suspicious emails should be candidate. An example of pipeline is proposed in the following diagram.

- First, the email traffic is prefiltered. Many elements can be considered to determine if an email is suspicious – it can be for instance the fact that the sender email address is unknown. If the email is suspicious, a graphical rendering is performed by the rendering engine. There exist many libraries and software to perform the rendering – chromedp is a popular option.
- The graphical rendering – or ‘screenshot’ – is then analysed by the Computer Vision engine. The capabilities of the engine depend on the features implemented: OCR (Optical Character Recognition) could be used to extract text (such as the toll-free phone number in the Geek Squad email scam), and a barcode scanner would be able to extract links from QR codes (such as the malicious link in the DHL phishing email).
- These features are then transmitted to a decision engine that will combine them and return a verdict.
- Finally, depending on the verdict, elements will be blocked according to a blocking policy, in order to prevent new attacks. Different elements may be blocked, such as the sender email address, email domain, sending IP and IP range. In the case of a malicious link, the URL and also the domain may be blocked.
Reverse Image Search to detect malicious content
Another approach that could be used would be to replace the Computer Vision engine and decision engine with a Reverse Image Search component coupled with a database of email screenshots.
Why this particular approach?
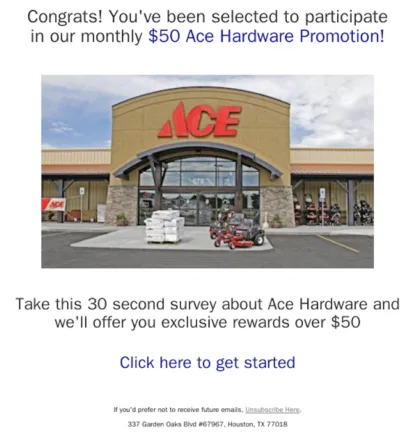
The reason is that Hornetsecurity analysts are confronted with sophisticated and recurring affiliation spam email campaigns impersonating well-known retail brands (Costco, Lowes, Walmart, Ace Hardware, etc.). One of the main challenges is that the content of the email is extremely variable from one to another – the spammers know all the tricks to add noise and hide the relevant content – while the visual representation of the email does not evolve much over time – but it does change.
Examples of variable content in an email
Two examples of such emails are displayed below, where the end user is prompted to click on a spammy link. While the emails are similar, they present some differences. The most obvious one is the change of the text color, first red then blue. There are, however, other changes that are more subtle: the relative size of the image, the spacing between the different blocks.

How to detect
To detect this kind of recurring spam, an approach would be that the analysts provision a database of known ‘spam’ screenshots, and then each time a suspect email is analysed, the Reverse Image Search component queries the database to know whether the email screenshot is known as ‘spam’. If this is the case, then elements are blocked to stop the campaign.
The Reverse Image Search component must be able to perform a ‘fuzzy search’ – in other words it must be resilient to small changes in the screenshot. The same principle can be used to detect other recurring malicious emails such as phishing – in this case, variants of the phishing campaign can be detected, such as a phishing email with a different QR code.

Conclusion
In the next articles, we will deep dive into the algorithms that can be used to implement a Reverse Image Search engine. This problem – also known as Duplicate Image Detection or Near-Duplicate Image Detection – has been widely studied by academics, and we will refer to the existing research literature.

