
How to Make the Undeniable Business Case for Backup
With the input of business-oriented personnel, you can determine how IT will deliver an appropriate business continuity design. To that end, you need to discover the capabilities of the technologies available to you.
Once you know that, you can predict the costs. You can take that analysis back to the business groups to build a final plan that balances what your organization wants for disaster recovery against its willingness to pay for it.
Mapping out your backup requirements will then help you plan software subscriptions to fulfil your needs. Hornetsecurity recognizes the necessity for multiple backup solutions and as such provides data backup and recovery service for all your critical Microsoft 365 services (Exchange mailboxes, SharePoint, OneDrive, Teams etc.) and also virtual machine backup.
Discovering the Technological Capabilities of Data Protection Systems
At this point, you have an abstract list of high-level business items. Few backup solutions target Line of-Business (LOB) applications. So, you need to break that list down into items that backup and replication programs understand.
To attract the widest range of customers, their manufacturers specify services and products that most organizations use. Common protections include:
- Windows Server and Windows desktop;
- UNIX/Linux systems;
- Database servers;
- Mail servers;
- Virtual machines;
- Cloud-based resources;
- Physical hardware configurations.
You’ll need to create a map from the prioritized business-level items to their underlying technologies. Bring in technical experts to ensure that you don’t miss anything. Gather input on what needs to happen in order to recover the various systems in use at your organization.
Many require more effort than a simple restore-from-backup procedure. Some examples:
- Active Directory;
- Log-based SQL recovery;
- Mail servers;
- Multi-tier systems;
- Cluster nodes.
Take input from line-of-business application experts as well as server and infrastructure experts. Seek out the experience of those that have faced a recovery situation with the systems that you rely on most. You might find exceptions or special procedures that would surprise generalists.
First Line of Defense: Fault-Tolerant Systems
Ideally, you would never need to enact a recovery plan. While you can never truly eliminate that possibility, you can reduce its likelihood with fault-tolerant systems. “Fault-tolerance” refers to the ability to continue functioning with a failed component.
Most fault-tolerant systems largely function at a low level, usually on the internal components of computer systems. To provide protection, they usually employ some method of hardware-level data duplication.
In the event of a failure, they use the redundant copy to continue providing expected functionality. Examples include multiple power supplies, disks, Network Interface Cards (NICs) and so forth.
However, until someone replaces the defective part, the system does not provide redundancy. Further failures will result in an outage and possibly data loss.
QR codes – The criminal’s new best friend
Storage technologies make up the bulk of fault tolerant systems. Not coincidentally, they also have the highest failure rate. You can protect short-term storage (main system memory) and long-term storage (spinning and solid-state disks).
System memory fault tolerance
To provide full fault tolerance, memory controllers allow you to pair memory modules. Every write to one module makes an identical copy to the other. If one fails, then the other continues to function by itself.
If the computer also supports memory hot-swapping and technicians have a way to access the inside without unplugging anything, then a replacement can be installed without halting the system.
Of course, system memory continues to be one of the more expensive components, and each system has a limited number of slots. So, to use fault-tolerant memory, you must cut your overall density in half.
Doubling the number of hosts presents more of a cost than most organizations want to undertake. Fortunately, memory modules have a low rate of total failure. It is much more likely that one will experience transient problems, which can be addressed with cheaper solutions.
Server-class computer systems usually support error-correcting code (ECC) memory modules. ECC modules incorporate technologies that allow for detection and correction of memory errors.
Some vendors provide proprietary technologies to defend against problems.
In most cases, you will choose ECC memory over fully fault-tolerant schemes. ECC cannot defend against module failure, but such faults occur rarely enough to make the risk worthwhile. ECC costs more than non-ECC memory, but it still has a substantially lower price tag than doubling your host purchase.
Hard drive fault tolerance
Hard drives, especially the traditional spinning variety, have a high failure rate. Since they hold virtually all of an organization’s live data, they require the most protection. Due to the pervasiveness of the problem, the industry has produced an enormous number of fault-tolerant solutions for hard drives.
RAID (redundant array of independent disk) systems make up the bulk of hard drive fault tolerance designs. These industry-standard designs use a combination of the following technologies to protect data:
Mirroring
Every bit written to one disk is written to the same location on at least one other disk. If a disk fails, the array uses the mirror(s).

Striping
Every bit written to one disk is written to the same location on at least one other disk. If a disk fails, the array uses the mirror(s).
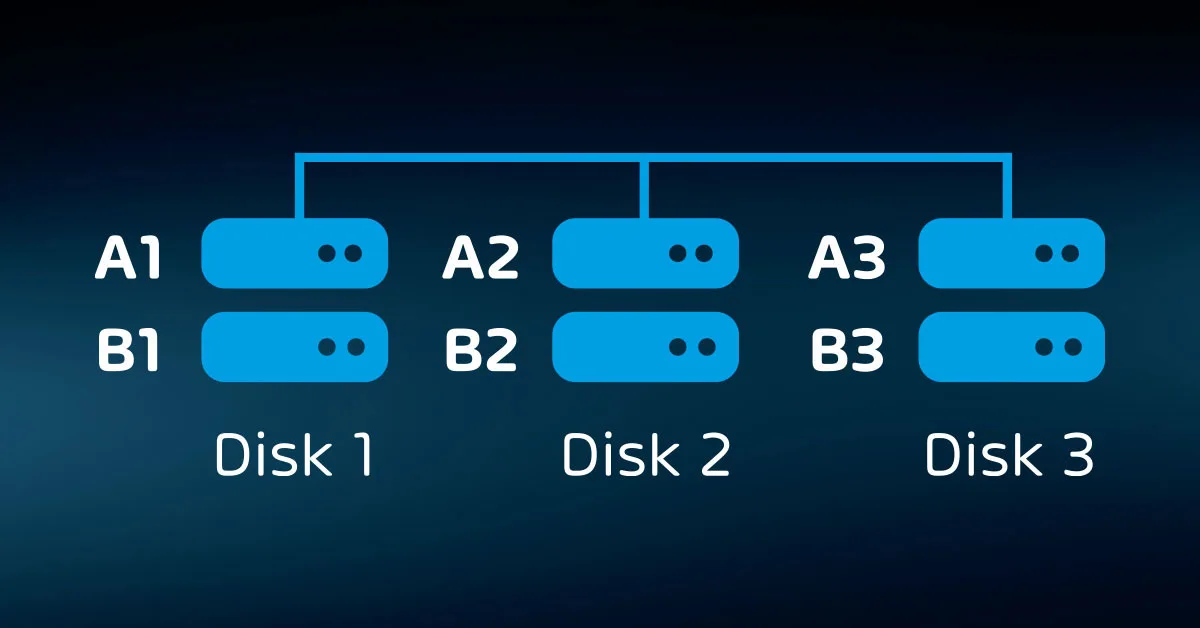
Parity
Parity also uses a striping pattern, with a major difference. One or more blocks in each stripe holds parity data instead of live data. The operating system or array controller calculates parity data from the live data as it writes the stripe.
If any disk in the array fails, it can use the parity data in place of the live data. A parity array can continue to function with the loss of one disk per parity block per stripe.

If you wish to use RAID, you can choose from a number of “levels”. Each level of RAID provides its own balance of redundancy, speed, and capacity. With the exception of RAID-0 (pure striping for performance, no redundancy), all RAID levels require you to sacrifice some available space for protection.
Disks present a relatively low expense when compared to system memory, and you have many expansion options beyond the base capacity of a system chassis. So, while RAID presents a higher cost per stored bit than single disk systems, it is usually not prohibitive.
You have several choices when it comes to RAID. Many levels have fallen out of favor due to insufficient protection in comparison to others, and some simply consume too much space for cost efficiency. You will typically encounter these types:
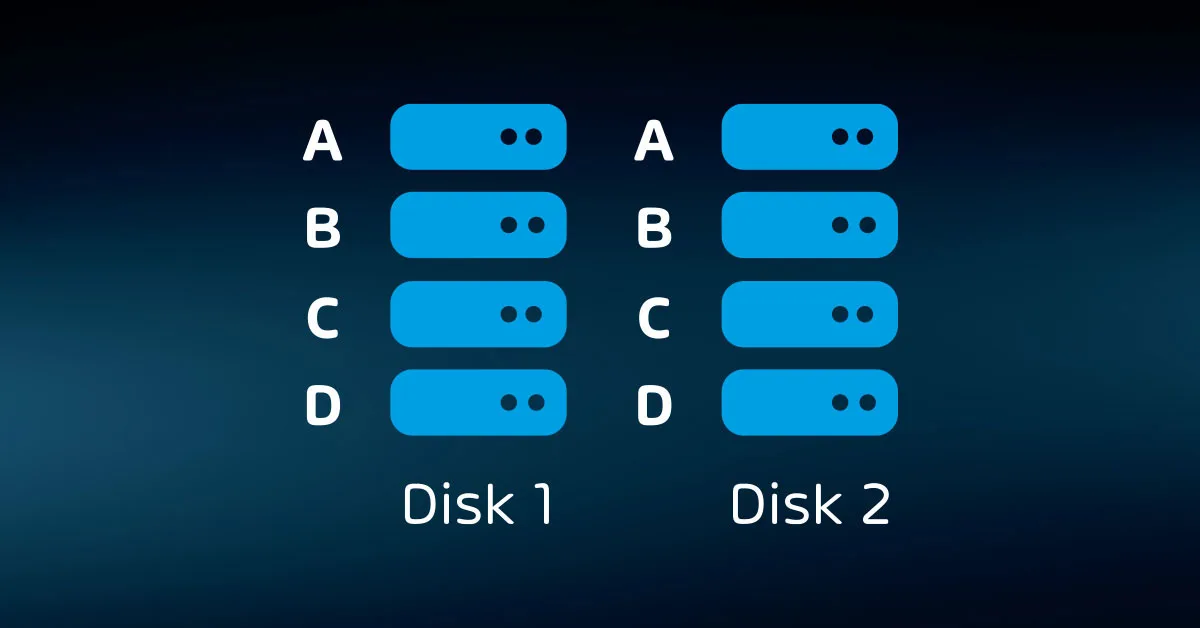
- RAID-1 – A simple mirror of two disks. Provides adequate protection, slightly lower than normal write speeds, higher than normal read speeds, and a 50% loss of capacity.
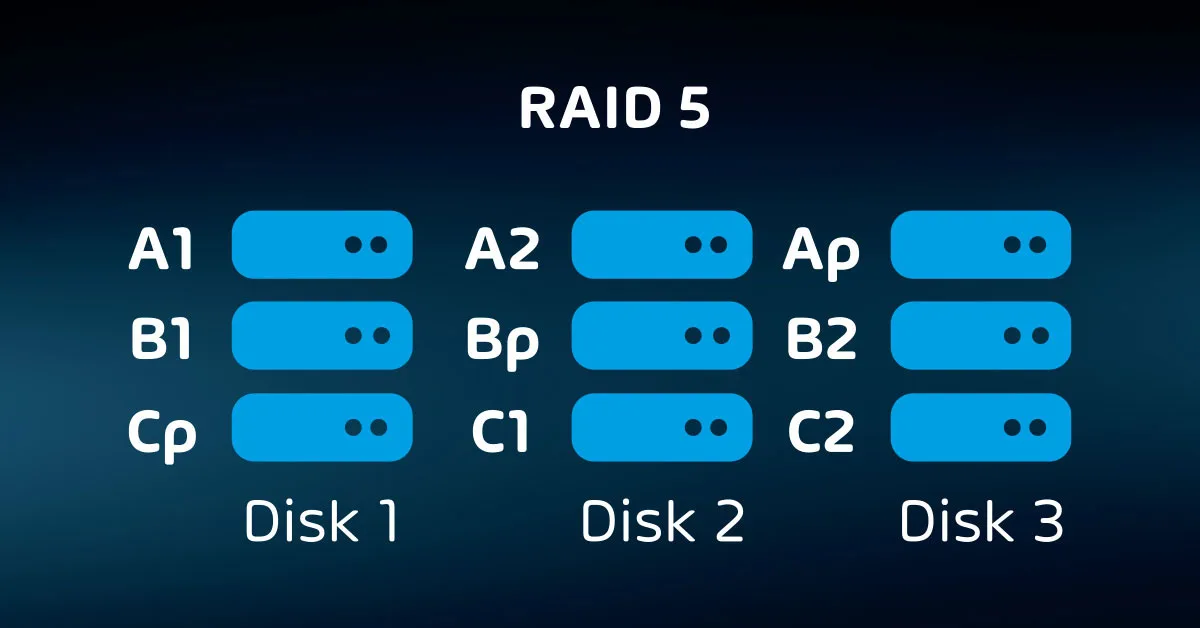
- RAID-5 – A stripe with a single parity block. Requires at least three disks. Each stripe alternates which disk holds the parity data so that in a failure scenario, parity calculations only need to occur for 1/n stripes. Can withstand the loss of a maximum of one disk. Provides adequate protection, above normal write speeds, above normal read speeds, and a loss of 1/nth capacity. Not recommended for arrays that use very large disks due to the higher probability of additional disk failure during rebuilds and the higher odds of a failure occurring between patrol reads (scheduled reads that look for bit failures).
- RAID-6 – Like RAID-5, but with two parity blocks per stripe. Requires at least four disks. Safer than RAID-5, but with similar concerns on large disks. Slower than RAID-5 and a capacity loss of 2/n.
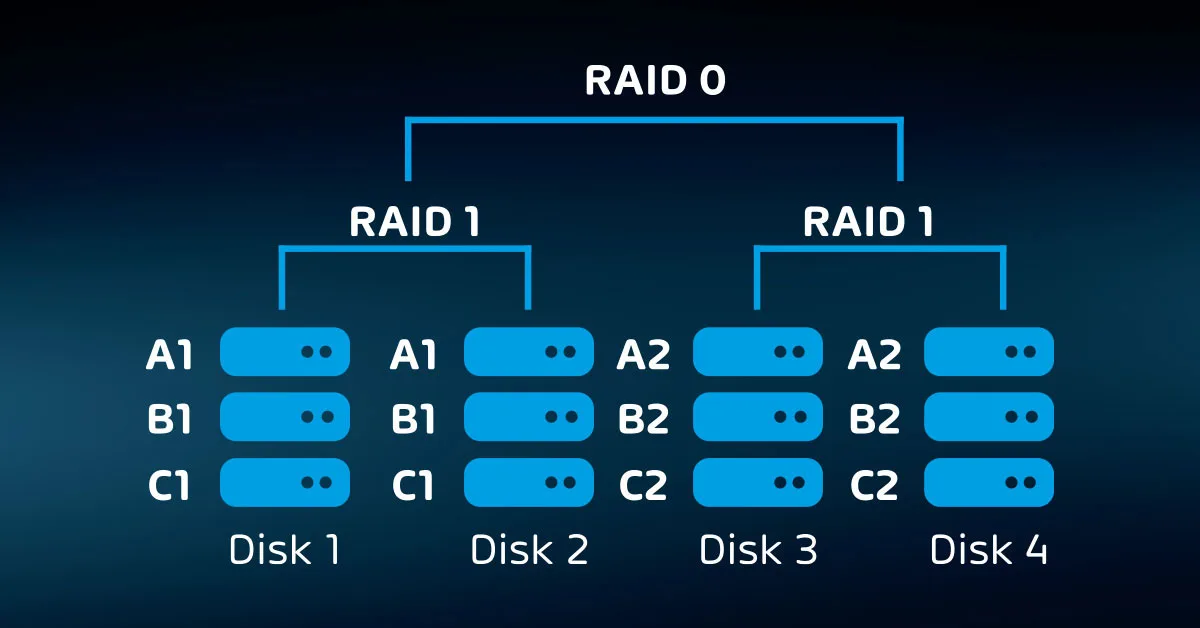
- RAID-10 – Disks are first paired into mirrors, then a non-parity stripe is written on one side of the mirror set, which is then duplicated to the corresponding mirror disk. Can function with the loss of one disk in each mirror but cannot lose two disks in the same mirror. Provides better performance and a higher safety rate than parity schemes, but at a loss of 50% of total drive capacity.
Due to the preponderance of drive failures and reduced performance of standardized redundancy schemes, many vendors have introduced proprietary solutions that seek to address particular shortcomings of RAID.
Whereas RAID works at the bit and block levels, most vendor-specific systems add on some type of metadata-level techniques to provide protection or performance enhancements.
You have an overwhelming number of choices when it comes to fault-tolerant disk storage, so keep a few anchor points in mind:
- Storage vendors naturally want you to buy their highest-cost equipment. Use planning tools to predict your capacity and performance needs before you start the purchasing process. Businesses frequently overestimate their space and performance requirements.
- You can almost always expand your storage after initial implementation. You do not need to limit yourself to the capacity of a single chassis as you do with system memory.
- Solid-state disks have a substantially lower failure rate than spinning disks. You can leverage hybrid systems that incorporate both as a way to achieve an acceptable balance of performance, redundancy, and cost.
The most important point: downtime costs money. Storage redundancy directly reduces the odds of an unplanned outage.
Advanced storage fault tolerance
The advent of affordable, truly high-speed networking (ten gigabit and above) has brought exciting new options in storage protection. Today’s networking speeds exceed even high-end storage equipment.
Once the sole purview of high-end (and very high-cost) storage area network (SAN) devices, you can now acquire chassis-level, and even datacenter-level, storage redundancy at commodity prices.
These technologies depend on real-time, or synchronous, replication of data. In the simplest design, two storage units mirror each other.
Systems that depend on them can either connect to a virtual endpoint that can fail over as needed or they connect to one unit at a time in an active/passive configuration. In more complex designs, control systems distribute data across multiple storage units and broker access dynamically.
We discuss real-time replication more completely in the article titled “How to Use Replication to Easily Achieve Business Continuity”.
The most advanced examples of these technologies appear in relatively new hyper-converged solutions. These use software to combine the compute layer with the storage layer on standard server-class computing hardware.
In most cases, they involve a hypervisor to control the software layer and proprietary software to control storage.
While costs for distributed storage and hyper-converged systems have declined dramatically, they remain on the higher end of the expense spectrum.
Unlike traditional discrete systems, you will need significant infrastructure and technical expertise to support them properly. You can consider the duplicated data in this fashion as a “hot” copy. It’s updated instantaneously and you can fail over to it quickly.
Some synchronous replication systems even allow for transparent failover or active/active use.
Application and operating system fault tolerance
At the highest layer, you have the ability to mirror an operating system instance to another physical system. To make that work, you must run the instance under a hypervisor capable of mirroring active processes.
It’s a complex configuration with many restrictions. Few hypervisors offer it, it won’t work universally, it won’t survive every problem, and the performance hit might make it unworkable for the applications that you want to protect most.
At a more achievable level, some applications allow a measure of fault tolerance through tiering. For instance, you can often run a web front-end for a database. You can use load balancers that instantly move client connections from one web server to another in the event of failure.
Some database servers also allow for multiple simultaneous instances that can instantly redirect connections to a functioning node. These technologies have greater functionality and feasibility than operating system fault tolerance.
In most cases, when an application offers its own in-built redundancy option (Exchange Server Database Availability Groups, or SQL Server Always On availability groups for example), these are always preferred over generic OS or Hypervisor high availability options, see below.
Caveats of fault tolerance
As you explore options for fault tolerance, you’ll quickly notice that it comes at a substantial cost. Almost all the technologies will require you to purchase at least two of everything. Most of them will necessitate additional infrastructure.
All of them depend on expertise to install, configure, and maintain. Those costs always need to be scoped against the cost of equivalent downtime.
The primary purpose of fault tolerance is to rely on duplicates to continue functioning during a failure. That has a negative side effect: your fault-tolerant solution might duplicate something that you don’t want.
For example, if ransomware attacks your storage system, having RAID or a geographically redundant SAN will not help you in any way. Even in the absence of a malicious actor, redundant systems will happily copy accidental data corruption or delete all instances of a vital e-mail on command.
While fault tolerance will serve your organization positively, it cannot stand alone. You will always need to employ a backup solution for asynchronous data duplication. However, you have options between fault tolerance and backup. Those technologies reside in the high availability category.
Second Line of Defense: High Availability
You can’t use fault tolerance for everything. Some systems have no way to implement it. Some have a prohibitively high price tag. Instead, you can deploy high-availability solutions. High availability has a more nebulous definition than fault tolerance. It applies less to actual technologies and more to outcomes.
Where fault tolerance means working through a failure without interruption, high availability measures actual uptime against expected uptime.
As an example, your organization sets a target of 99.99% annual availability for a system that they want always to work. To achieve that, you would need to ensure that the system does not experience more than a few minutes of total downtime in the course of a year.
365 days times 99.99% equals 364.9635 days of uptime, which allows a little less than 48 minutes. That’s an aggressive goal.
When you build high availability goals, ensure that you distinguish whether or not you include planned outages in the metric. If you include them, then you may substantially reduce your tolerance for failures.
If systems expected achieve 99.99% uptime require five minutes per month to fail from active systems to backup systems during patch cycles and you include that in the metric, then they will violate the availability expectation by 12 minutes per year even without unexpected outages.
Along with adjusting for planned maintenance, you can also set the scope of availability. As an example, you can keep the 99.99% goal, but indicate that it only applies from 6:00 AM to 6:00 PM on weekdays. You could exclude company holidays.
Take care to follow two critical steps:
- Clearly outline any non-obvious exceptions. If you set an expectation of 99.99% in large font and subtly list conditions below, then you will eventually experience the wrath of someone that feels deceived and betrayed. Avoid that from the beginning.
- Define a precise standard for “uptime”. Favor the user experience in these results, but also have something that you can objectively measure. For instance, “customer can place a complete order on the website” works well as an abstract goal, but how do you measure that? If a system failure would have prevented a customer from ordering, but no customer tried, does that count as an outage? If a customer order fails, how do you know if the system was at fault?
From the technology angle, any tool that specifically helps to improve uptime falls under the high availability umbrella. All fault-tolerant technologies qualify. However, you also have some that allow a bit of downtime in exchange for reduced cost, wider application, and simpler operation. Among these, clustering is generally the most common.
High Availability with Clustering
Clustering involves using multiple computer or appliance nodes, usually in an active/passive configuration, to host a single-instance resource. Some examples that depend on Microsoft’s failover clustering technology:
Microsoft SQL
A clustered Microsoft SQL database runs on one of many nodes. In a planned failover, the database becomes unavailable for a few seconds while its active node stops and one of the passive nodes start. In the event of active node failure, the database is offline for a few seconds while a passive node starts it. Active transactions might drop in an unplanned failover.
Hyper-V
A clustered virtual machine can quickly move online (Live Migration) or offline (Quick Migration) to another node in a planned failover. If its active node fails, the virtual machine crashes but another node can quickly restart it.
File server
The standard clustered Microsoft file server hosts through an active node, with planned and unplanned failovers occurring quickly. Microsoft also provides a scale-out file server, which operates in a more fault-tolerant mode.
Storage Spaces Direct
Commonly called “S2D”, Storage Spaces Direct is Microsoft’s distributed file system offering. It works on Windows Server for plain storage needs. Azure Stack HCI also implements it to provide a complete hyper-converged infrastructure solution.
You will find clustering technologies in other operating systems, hypervisors, and physical appliances. Remember that these differ from fault-tolerance in that they allow some downtime. However, they greatly reduce downtime risks when compared to standalone systems.

Caveats of clustering
Clustering provides a duplicate of the compute layer. It ensures that a clustered workload has somewhere to operate. It does not make any copies of data. Without additional technology, a critical storage failure can cause the entire cluster to fail.
Because of the necessity of hardware duplication, clustering costs at least twice as much as operating without a cluster. You might also need to purchase additional software features in order to enable a clustered configuration. Clustering requires staff that know how to install, configure, and maintain it.
You must also take care that the backup solution you choose can properly protect your clustered resources. Solutions such as Hornetsecurity’s VM Backup protect virtual machine clusters. You can sometimes successfully employ a backup solution that doesn’t interoperate with your high-availability solution, but it will require significantly more administrative effort.
High Availability With Asynchronous Replication
You can employ technologies that periodically copy data from one storage unit to another. Asynchronous replication can use a snapshotting technique to maintain complete file system consistency. Some replication applications use a simple file-copy mechanism, which works well enough for basic file shares but not for applications.
Some applications have their own asynchronous replication built in. Microsoft’s Active Directory will automatically send updates between domain controllers. Most SQL servers have a set of replication options. Microsoft Hyper-V can create, maintain, and control virtual machine replicas.
You can consider data created by asynchronous replication as a “warm” copy. It does require some sort of process to bring online after a failure, but you can place it in service quickly.
Caveats of asynchronous replication
Unlike clustering, asynchronous replication requires some human interaction to switch over to a copy after a failure. Clustering technologies use some sort of control technique to prevent split-brain situations in which two copies run actively and simultaneously. Most replication systems have no built-in way to do that. So, if you choose to implement replication, ensure that you plan accordingly.
Replication shares the main drawbacks of clustering: it requires duplicated hardware, special software, and expertise. It also does not protect against data corruption, including ransomware.
The Universal Fail-Safe – Backup
Out of all available disaster recovery and business continuity technologies, only backup is both sufficient on its own and necessary in all cases. You can safely operate an organization without any fault-tolerance or high availability technologies, but you cannot responsibly omit data backup and recovery service.
Please note that the following section contains many terms you will need to know to understand. The glossary contains all the definitions you’ll require.
Before you start shopping, ensure that you understand common backup terms:
- Full backup – A complete, independent duplication of data that you can use to recover all data without any dependency on any other data.
- Differential backup – An abbreviated backup that only captures data that changed since the most recent full backup. Usually operates at the file level.
- Incremental backup – An abbreviated backup that only captures data that changed since the most recent backup of any kind. Usually operates at the file level.
- Media – Storage for backups. Intended as a catch-all word whether you save to solid state drives, magnetic disks, tapes, optical discs, or anything else.
- Delta – In backup parlance, delta essentially means “difference”. Most backup vendors use it to mean a measurement of how a file or a block has changed since the last backup. You can reasonably expect the term “delta” to designate technology that operates below the file level.
- Crash-consistent – A crash-consistent backup captures a system’s data at a precise point in time. It carries the name “crash-consistent” because, if you restore to such a backup, the system will act exactly as though it had crashed when the backup was taken. A crash-consistent backup does not protect any running processes, nor does it give them any opportunity to save active data. However, it captures all files exactly as they were at that moment.
- Application-consistent – An application-consistent backup interacts with applications to give them an opportunity to save active data for the backup. All other data, including that of applications that the backup applications cannot notify, will save in a crash-consistent state.
- Restore – The act of retrieving data from a backup. Restoration can return data to a live system or to a test system. Most tools allow you to choose between complete and partial restores.
- Rotation – Re-using backup media, usually by overwriting older backups. Some backup software has intricate rotation options.
Not everyone agrees on the definitions of “crash-consistent” and “application-consistent”, and some vendors have introduced their own labels.
Ensure that you understand how any given vendor uses these terms when you study their products and talk to their representatives. Also have them explicitly define what they mean by “delta” in their solutions.
As you explore backup solution choices, you need to use the plan created by your business teams as a guideline. You want to try to satisfy all requirements for data protection and retention. Consider these critical components of data backup and recovery service technologies:
- Backups must create a complete, standalone duplicate of data;
- Backups must maintain multiple unique, non-interdependent copies of data;
- Backups should complete within your allotted time frame;
- Backups should provide application-consistent options;
- Backups should work with the type of backup media that you want to use;
- Backups should work with your cloud providers, both to protect your cloud resources and to back up to your.
The above list only constitutes a bare minimum. Realistically, all backup vendors know that they need to hit these targets, so only a few will miss. Usually, those are the built-in free options or small hobbyist-style projects. You will find the greatest variances among the last two items.
Products will distinguish themselves greatly in operation and in optional features. You should avail yourself of trial software to experience these for yourself. Some things to look for:
Ease of operation (especially restores)
In a disaster, you cannot guarantee the availability of your most technically proficient staff, so your backup tool should not require them.
Speed of operations
Backup and restore operations need to complete in a reasonable amount of time. However, they cannot sacrifice vital functionality to achieve that. Most backup vendors utilize some sort of deduplication technology to reduce time and capacity needs, but you absolutely must have a sufficient number of non-interdependent copies of your data.
Retention lengths
Most backup applications allow an infinite number of backups – except in their free editions. If your organization won’t allow you to spend money on backup software, that might prevent you from achieving their requirements.
Support for the products that you use
As mentioned earlier in this article, very few backup applications know anything about line-of-business software. However, they should handle your operating systems and hypervisors. Some will have advanced capabilities that target common programs, such as mail and database servers.
If you choose a solution that does not natively handle your software, ensure that you know how to use it to perform a proper backup and restore.
Offsite support
Because you will use backup to protect against the loss of your primary business location, your backup tool needs to have some method that allows you to take backup data offsite. Traditionally, that meant some sort of portable media.
Today, that also means transmitting to an alternative location or a cloud provider.
Support for alternative hardware
After a disaster, you probably won’t have the luxury to restore data to the same physical hardware that it protected. Make sure that your backup application can target replacement equipment.
Technical support options
Hopefully, you’ll never need to call support for your backup product. However, you don’t know who might need to perform a restore. That task might fall to a person that will need help. You also need to consider future product updates and the possibility of bugs that need attention.
Ensure that you understand your backup provider’s support stance and process. Check public sites and forums for reviews by others, although remember that happy people rarely say anything, and angry people often exaggerate.
Look for complaints that highlight specific problems. If possible, try to talk to someone in support before purchase.
Consider data created by backup as a “cold” copy. You must take some action to transition the data from its backup location before you can use it in production. It usually has a much higher time distance from the failure point than replication.

Closing the Planning Phase
You have now seen all the basic concepts and have enough knowledge to tackle the planning phase of your disaster recovery strategy.
To properly protect your virtualization environment and all the data, use Hornetsecurity VM Backup to securely back up and replicate your virtual machine.
We ensure the security of your Microsoft 365 environment through our comprehensive 365 Total Protection Enterprise Backup and 365 Total Backup solutions.
For complete guidance, get our comprehensive Backup Bible, which serves as your indispensable resource containing invaluable information on backup and disaster recovery.
To keep up to date with the latest articles and practices, pay a visit to our Hornetsecurity blog now.
Conclusion
In conclusion, crafting an unassailable business case for backup is a multifaceted endeavor. By collaborating with business-focused experts, understanding available technology capabilities, and predicting costs, you pave the way for a robust business continuity strategy.
This process harmonizes the organization’s disaster recovery aspirations with its financial constraints, ensuring a comprehensive, cost-effective solution. With a well-founded plan, you can confidently safeguard your business against unforeseen disruptions.
FAQ
What is data backup and recovery services?
Data backup and recovery services ensure your data’s safety and availability in case of loss. It involves duplicating and archiving computer data to prevent data loss due to corruption or deletion.
What does a data recovery service do?
Data recovery service providers specialize in recovering lost data by understanding data storage and restoration techniques. Opting for data recovery software is a safer choice compared to physical recovery attempts. Hornetsecurity offers a comprehensive solution for your data backup and recovery needs.
Is it safe to use a data recovery service?
Opting for data recovery software is a safer choice compared to physical recovery attempts. Hornetsecurity offers a comprehensive solution for your data backup and recovery needs.

