
Erkennung von Cyber-Bedrohungen mit Computer Vision (Teil 2)
Einführung
In unserem letzten Artikel haben wir untersucht, wie Computer Vision die Cybersicherheit auf ein neues Level heben kann, indem sie E-Mails und Webseiten nicht nur auf ihren Inhalt, sondern auf ihr visuelles Erscheinungsbild hin analysiert. Wir haben beleuchtet, wie dieser Ansatz raffinierte Angriffe entlarven kann, die durch klassische Inhaltsprüfungen möglicherweise unter dem Radar bleiben. Außerdem haben wir ein System zur umgekehrten Bildersuche vorgestellt, das bösartige Kampagnen aufspürt, indem es Screenshots eingehender E-Mails mit bereits bekannten Bedrohungen vergleicht – quasi ein visuelles Gedächtnis für digitale Gefahren.
Dieser zweite Teil der Serie taucht nun tiefer in die technischen Herausforderungen ein, die bei der Erkennung von Bild-Duplikaten und fast identischen Kopien auftreten. Denn während exakte Kopien sich problemlos aufspüren lassen, sind Angreifer alles andere als unkreativ: Sie modifizieren Bilder gezielt, um der Erkennung zu entgehen. Ein Phishing-Angriff kann beispielsweise auf einer Vorlage basieren, die nur minimal verändert wurde – vielleicht ein anderer Farbton hier, ein leicht verschobenes Logo dort –, doch die schädliche Absicht bleibt bestehen.
Um solche Täuschungsmanöver aufzudecken, werfen wir einen Blick auf zwei essenzielle Techniken zur Bildähnlichkeitserkennung: hashbasierte Verfahren und Farbhistogramme. Diese Methoden sind das Fundament für ausgefeiltere Systeme, die wir im nächsten Artikel dieser Reihe vorstellen. Beide Ansätze bringen ihre eigenen Stärken und Schwächen mit, insbesondere wenn es um die Balance zwischen Präzision, Geschwindigkeit und Widerstandsfähigkeit gegenüber gezielten Bildveränderungen geht.
Erkennung von Bild-Duplikaten für die Bedrohungsanalyse
Was ist ein Bild-Duplikat?
Ein Bild-Duplikat kann entweder eine exakte Kopie oder eine modifizierte Version eines Originalbildes sein. In Cybersicherheitskampagnen greifen Angreifer gerne zu einem bewährten Trick: Sie nehmen ein Bild und verändern es gerade so weit, dass Sicherheitsfilter ausgetrickst werden, während es für menschliche Betrachter immer noch vertraut wirkt. Ein kleiner Tweak hier, eine minimale Größenanpassung dort, vielleicht ein paar zusätzliche Textelemente oder ein unauffälliger Filter – die Manipulationen sind subtil, aber wirkungsvoll.
Das führt zu einer kniffligen Herausforderung: Während das menschliche Auge die Verwandtschaft zwischen Original und modifizierter Version sofort erkennt, tun sich herkömmliche Sicherheitssysteme schwer damit. Wie lässt sich diese visuelle Ähnlichkeit also automatisch erfassen, sodass Maschinen sehen, was für uns offensichtlich ist?
Wie unser Reverse Image Search System funktioniert
Unser Reverse Image Search System wurde entwickelt, um Duplikate und Variationen bekannter bösartiger Bilder zu identifizieren. Wir unterhalten eine Datenbank mit bekannten bösartigen E-Mail-Screenshots, die zur Analyse eingehender E-Mails verwendet wird.
Wenn eine neue E-Mail eintrifft, vergleicht das System ihre visuelle Darstellung mit dieser Datenbank, um mögliche Duplikate oder Variationen bekannter Bedrohungen zu identifizieren. Anstatt Bilder einfach als Duplikate oder Nicht-Duplikate zu klassifizieren, berechnet unser System für jeden Vergleich einen Ähnlichkeitswert zwischen 0 und 1.
Diese stufenlose Skalierung bietet eine genauere Kontrolle über die Erkennungsschwellenwerte, so dass wir die Empfindlichkeit unseres Systems auf verschiedene Bedrohungsszenarien abstimmen können.
Blockieren bösartiger Elemente
Wenn eine Bedrohung durch Bild-Duplikate erkannt wird, löst unsere Blockierungsrichtlinie automatisch Abwehrmaßnahmen aus, die weitere Angriffe verhindern, indem sie zugehörige Elemente wie IP-Adressen, URLs und Domänen blockieren.
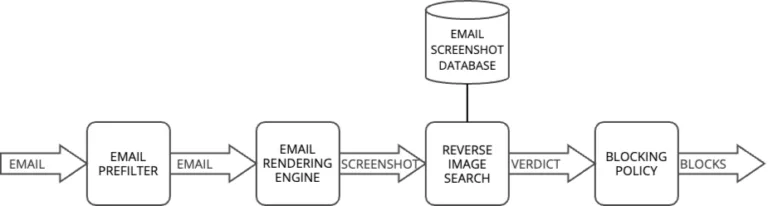
Strategie für die Erkennung von Pipelines
Unsere Erkennungspipeline folgt einer progressiven Filterstrategie, die ein Gleichgewicht zwischen Geschwindigkeit und Genauigkeit herstellt. Auf den ersten Ebenen werden schnelle Erkennungstechniken eingesetzt, die zwar möglicherweise weniger präzise sind, aber große Mengen von E-Mails schnell verarbeiten können. Nur die verdächtigsten E-Mails werden an rechenintensivere Techniken weitergeleitet. Dieser Trichteransatz optimiert die Ressourcennutzung und gewährleistet gleichzeitig eine effektive Erkennung von Bedrohungen.
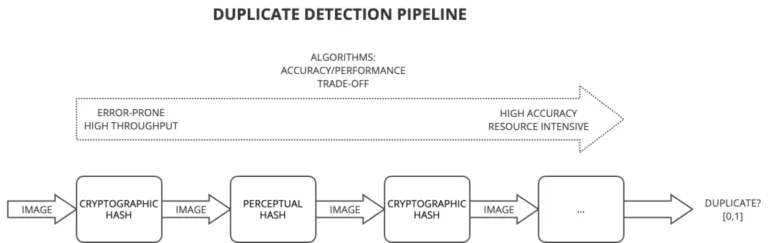
Referenz-Bilder
In diesem Artikel verwenden wir zur Demonstration jeder Erkennungstechnik eine einheitliche Reihe von Referenzbildern, um die Effektivität und die Fähigkeiten der einzelnen Techniken besser vergleichen zu können.
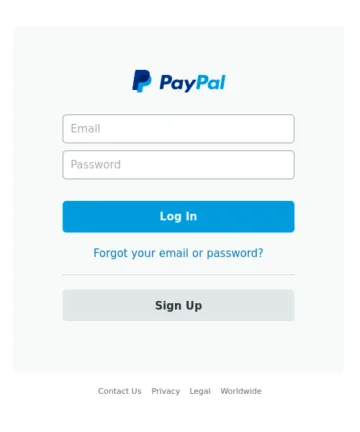
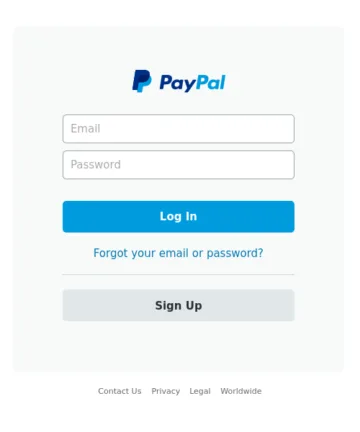
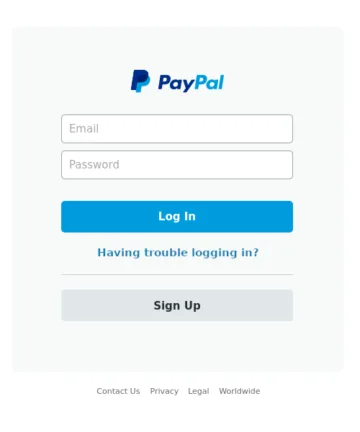
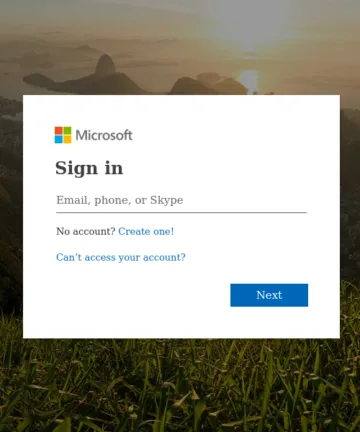
Die vier Bilder oben dienen als Referenzbilder. Bilder A und B zeigen identische Kopien. Bild C ist eine Variante mit geringfügigen Textänderungen im Abschnitt zur Passwortwiederherstellung. Bild D zeigt eine völlig andere Szene.
Hash-basierte Erkennungstechniken
Hash-basierte Verfahren zur Erkennung von Bild-Duplikaten bezeichnen diverse Algorithmen, die der Identifizierung von Bild-Duplikaten und ähnlichen Bildern dienen, indem für jedes Bild eindeutige Signaturen, so genannte Hashes, erzeugt werden. Solche Hashes fungieren als kompakte Repräsentationen des Bildinhalts sowie der Bildmerkmale.
Kryptographische Hash-Funktionen
Die Grundidee hinter Hash-basierten Techniken besteht darin, ein Bild in eine Bitfolge fester Länge (Hash-Code) umzuwandeln, und zwar so, dass ähnliche Bilder ähnliche Hash-Codes ergeben. Das Ergebnis: Exakte Duplikate erzeugen identische Hash-Codes, so dass sie leicht identifiziert werden können. Die einfachsten Hash-Algorithmen, die wir verwenden können, sind kryptographische Funktionen, wie MD5 oder SHA-1.
Die Tabelle unten zeigt die MD5-Hashes der Bilder. Wie erwartet, werden nur exakte Duplikate als Bild-Duplikate erkannt. Das liegt daran, dass die kryptografischen Hash-Funktionen, , die ursprünglich für Sicherheit und Datenintegrität entwickelt wurden, den Avalanche-Effekt aufweisen: Schon eine kleine Änderung in der Datei führt zu einem deutlich anderen Hash-Wert.
| Bild | MD5-hash |
|---|---|
| A (Original) | fb5e836185a7b3044e0fbb729b9e5a45 |
| B (exaktes Duplikat) | fb5e836185a7b3044e0fbb729b9e5a45 |
| C (Beinahe-Duplikat) | 0adc239afeeddab5812b9630dba97883 |
| D (unterschiedlich) | 153f8ef8a277f9c11d4f18ba9ae6df6a |
Übersicht über Perceptual Hashing
Ganz anders als kryptographische Hashes bieten wahrnehmungsbasierte Hash-Techniken einen sehr flexiblen Ansatz, welcher die inhärenten Varianten in Bildern auf Grundlage von Modifikationen, Skalierung und anderen Transformationen berücksichtigt.
Perceptual Hashing ist eine Art von Locality-Sensitive Hashing (LSH), einer breiteren Klasse von Algorithmen, die für Aufgaben wie Datenclustering und die Suche nach dem nächsten Nachbarn entwickelt wurden. Im Gegensatz zu herkömmlichen Hash-Funktionen stellt LSH sicher, dass kleine Variationen in den Quelldaten zu kleinen Variationen oder gar keinen Variationen im Hash führen. Dank dieser Eigenschaft eignet sich Perceptual Hashing besonders gut für die Identifizierung visuell ähnlicher Bilder, selbst wenn diese geringfügigen Transformationen unterzogen wurden.
Lassen Sie uns eine der einfachsten Wahrnehmungs-Hash-Funktionen untersuchen: Average Hash.
Average Hash: Eine einfache wahrnehmungsbasierte Hash-Methode
Average Hash vereinfacht komplexe Bilder in eine kompakte Darstellung, wobei ihre wesentlichen Merkmale erhalten bleiben. Die Schritte dieser Technik sind wie folgt:
- Vorverarbeitung des Bildes: Das Bild wird zunächst auf eine Standardgröße gebracht (8×8 Pixel, 64 Gesamtpixel). Diese Größenanpassung sorgt für eine einheitliche Verarbeitung und minimiert den Einfluss von kleinen Details.
- Graustufen-Konvertierung: Das in der Größe veränderte Bild wird dann in Graustufen umgewandelt. Die Graustufenkonvertierung vereinfacht das Bild, macht es widerstandsfähiger gegen Farbschwankungen und verbessert die Effizienz des Algorithmus.
- Berechnung des durchschnittlichen Pixelwerts: Der durchschnittliche Pixelintensitätswert des Graustufenbildes wird berechnet. Dieser Wert dient als Basis für die Bestimmung, ob einzelne Pixel dunkler oder heller als der Durchschnitt sind.
- Erzeugen eines Hash-Codes: Die Intensität eines jeden Pixels wird mit der durchschnittlichen Intensität verglichen. Wenn das Pixel heller ist, wird ihm der Wert 1 zugewiesen, andernfalls 0. Diese Binärwerte werden zu einer 64-Bit-Ganzzahl verkettet, wodurch ein Hash-Code entsteht, der die charakteristischen visuellen Merkmale des Bildes darstellt.
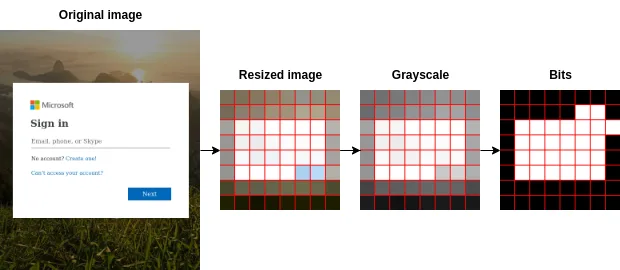
Hash-Vergleich und Ähnlichkeitsbewertung
Die folgende Tabelle zeigt die Hashwerte der einzelnen Bilder mit der Funktion Average Hash: Der Hashwert des modifizierten Bildes ist bis auf zwei Bits fast identisch mit dem des Originals.
| Bild | Durchschnittlicher Hash |
|---|---|
| A (Original) | ffc7ff8181c3ffff |
| B (exaktes Duplikat) | ffc7ff8181c3ffff |
| C (Beinahe-Duplikat) | ffc7ff8080c3ffff |
| D (unterschiedlich) | 00067f7e7e7e0000 |
Der einfachste Ansatz für den Vergleich zweier Bilder ist die Verwendung der Hamming-Distanz für ihre jeweiligen Hashes. Dieser Abstand misst die Anzahl der unterschiedlichen Bitpositionen zwischen den Hashes. Identische Bilder ergeben zum Beispiel einen Hamming-Abstand von Null. Zur Manipulation von Scores wird eine alternative Berechnung verwendet:
average_score(a, b) = 1 - (Hamming(a, b) / 64) Diese Formel bietet eine praktische Skala von 0 bis 1, wobei 0 für völlig unähnliche Bilder steht und 1 für exakte Duplikate. Die folgende Tabelle zeigt die Hamming-Distanzen und die entsprechenden Punktzahlen mit dem Originalbild. Anschließend muss nur noch ein Schwellenwert festgelegt werden, ab dem zwei Bilder als Duplikate eingestuft werden.
| Bild | Hamming-Abstand zu Bild A | Entfernung zu Bild A punkten |
|---|---|---|
| B (exaktes Duplikat) | 0 | 1.000 |
| C (Beinahe-Duplikat) | 2 | 0.969 |
| D (unterschiedlich) | 50 | 0.219 |
Beschränkungen des perzeptiven Hashings
Während sie bei der Erkennung von exakten oder Beinahe-Duplikaten effektiv sind, können Wahrnehmungshashes bei veränderten Bildern, bei Transformationen wie Rotation oder Skalierung, Schwierigkeiten bereiten.
Darüber hinaus können Wahrnehmungs-Hashing-Methoden gelegentlich zu falsch positiven oder negativen Ergebnissen führen, was sich auf die Genauigkeit auswirkt, insbesondere wenn es um Bilder geht, die zwar ähnliche visuelle Elemente, aber unterschiedliche semantische Inhalte haben. So schlugen Hao et al. in „It’s Not What It Looks Like: Manipulating Perceptual Hashing based Applications“ eine Reihe von Angriffsalgorithmen vor, um perzeptive Hashing-Techniken zu unterlaufen.
Um diese Einschränkungen auszugleichen, wird perzeptuelles Hashing oft mit inhaltsbasierten Techniken kombiniert, z. B. mit Farbhistogrammen, die im nächsten Abschnitt vorgestellt werden.
Farbhistogramme
Eine inhärente Einschränkung der zuvor vorgestellten durchschnittlichen Hash-Technik ist die Vernachlässigung der Bildfarben aufgrund ihrer Graustufen-Natur. Ein vielversprechender Weg zur Verbesserung unseres Systems ist daher die Implementierung eines inhaltsbasierten Ansatzes, der sich ausschließlich auf Farben konzentriert und Farbhistogramme verwendet.
Bei diesem Ansatz geht es darum, die Verteilung der in einem Bild vorhandenen Farben zu erfassen und als Histogramm darzustellen. Durch die Quantifizierung des Vorkommens jeder Farbe im Bild bietet die Farbhistogrammtechnik ein leistungsstarkes Werkzeug zur Identifizierung von Bildern mit ähnlichen Farbmustern.
Von einem Bild zu Histogrammen
Die Berechnung von Farbhistogrammen aus einem Bild umfasst mehrere Schritte:
- Bildvorbereitung: Konvertieren Sie das Bild in einen geeigneten RGB-Farbraum und verkleinern Sie es aus Leistungsgründen.
- Quantisierung: Reduzieren Sie die Anzahl der einzelnen Farben im Bild, während die visuelle Qualität insgesamt erhalten bleibt. Dies hilft uns, Speicherplatz zu sparen und die Rechenkomplexität zu verringern. Wir verwenden eine reduzierte Farbpalette von 16 Farben, die für eine Vielzahl von Aufgaben entwickelt wurde.
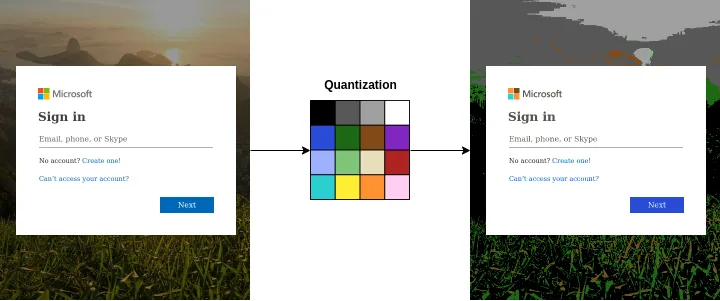
- Zählen der Pixel: Zählen Sie die Anzahl der Pixel, die in jeden der 16 Farbbereiche fallen.
- Normalisierung: Um sicherzustellen, dass die Histogramme unabhängig von der Größe des Bildes sind, normalisieren wir die Werte, indem wir die Anzahl der Pixel jeder Farbe durch die Gesamtzahl der Pixel im Bild dividieren.
Um das Verständnis dieser Technik zu erleichtern, zeigt die folgende Tabelle partielle Farbhistogramme für die vier Bilder, die nur vier der sechzehn Farben zeigen.
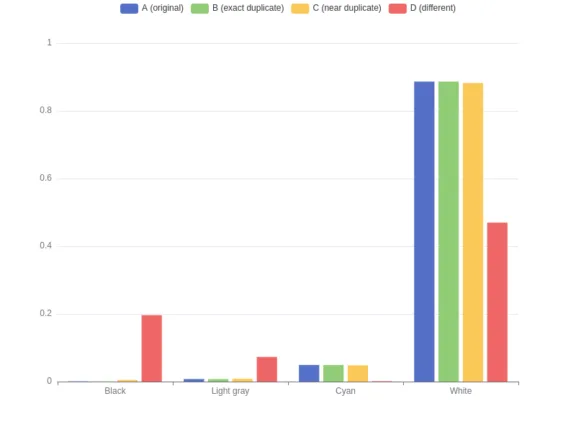
Histogrammvergleich und Ähnlichkeitsbewertung
Ähnlich wie bei den Hashes berechnen wir die Abstände zwischen den Farbhistogrammen mithilfe des Manhattan-Abstands – auch L1-Abstand genannt -, bei dem die Summe der absoluten Unterschiede zwischen den Werten in den Histogrammen berechnet wird. Wenn Sie diesen Abstand zum Vergleich von Bildern verwenden, ergeben sich bei ähnlichen Farbverteilungen kleinere Abstände. Im entgegengesetzten Extremfall, wenn zwei Histogramme völlig unterschiedlich sind, beträgt der L1-Abstand 2 (die Summe der beiden normalisierten Histogramme). Wie schon beim Durchschnittswert bevorzugen wir auch hier eine alternative Berechnung.
L1_dist(a, b) = abs(a[0] - b[0]) + abs(a[1] - b[1]) + ... + abs(a[15] - b[15])
hist_score(a, b) = 1 – L1_dist(a, b) / 2 Diese Formel bietet eine bequeme Skala von 0 bis 1, wobei 0 für eine völlig unähnliche Farbverteilung im Bild steht und 1 für eine exakt gleiche Farbverteilung. Die folgende Tabelle zeigt die L1-Distanz und die Histogramm-Scores mit dem Originalbild.
| Bild | L1 Distanz zu Bild A | Histogram-Scores |
|---|---|---|
| B (exact duplicate) | 0.000 | 1.000 |
| C (near duplicate) | 0.011 | 0.994 |
| D (different) | 1.024 | 0.488 |
Beschränkungen von Farbhistogrammen
Dieser Ansatz hat eine offensichtliche Schwäche: Er betrachtet lediglich die Verteilung der Farben im Bild, ohne deren genaue Anordnung zu berücksichtigen. Das kann dazu führen, dass zwei Bilder als ähnlich eingestuft werden, obwohl ihre Inhalte völlig unterschiedlich sind. Zudem spielt die Wahl der reduzierten Farbpalette eine entscheidende Rolle – je nachdem, wie viele Farben erhalten bleiben, können die Ergebnisse stark variieren. Während die bisher besprochenen Methoden – darunter Perceptual Hashing und Farbhistogramme – durchaus Hinweise auf Bildähnlichkeiten liefern, bleibt eine zentrale Frage offen: Sind die tatsächlich abgebildeten Objekte auch wirklich vergleichbar? Genau dieser Aspekt steht im Mittelpunkt des nächsten Artikels.

Fazit
In diesem Artikel haben wir zwei grundlegende Techniken zur Erkennung von Duplikaten und Beinahe-Duplikaten untersucht: Hash-basierte Methoden und Farbhistogramme. Diese Ansätze bieten zwar effiziente anfängliche Filtermöglichkeiten, haben aber jeweils ihre Grenzen. Wahrnehmungsbasierte Hash-Verfahren können anfällig für bestimmte Veränderungen sein, und Farbhistogramme sind zwar nützlich für die Analyse von Farbverteilungen, berücksichtigen aber nicht die räumliche Anordnung der visuellen Elemente.
Diese Techniken eignen sich gut als schnelle Screening-Mechanismen in unserer Erkennungspipeline und bieten ein gutes Gleichgewicht zwischen Recheneffizienz und annähernder Übereinstimmung. Für wichtige Sicherheitsentscheidungen benötigen wir jedoch ausgefeiltere Methoden, um zu überprüfen, ob die entdeckten Ähnlichkeiten tatsächlich auf Bedrohungen durch Bild-Duplikate hinweisen.
In unserem nächsten Artikel werden wir uns mit inhaltsbasierten Ansätzen befassen, die die tatsächlichen visuellen Elemente und ihre Beziehungen innerhalb der Bilder analysieren. Diese Methoden sind zwar rechenintensiver, bieten aber die hohe Genauigkeit, die für eine zuverlässige Erkennung von Duplikaten erforderlich ist. Wir werden untersuchen, wie diese Techniken uns helfen können, Varianten bekannter Bedrohungen sicher zu identifizieren, selbst wenn Angreifer ausgeklügelte Modifikationstechniken einsetzen, um die Erkennung zu umgehen.

