
Cyberbedrohungen mit Computer Vision erkennen (Teil 1)
Einführung
Willkommen zum ersten Artikel unserer vierteiligen Serie über die Erkennung von Cyberbedrohungen mit Computer Vision. In diesem Artikel erläutern wir, warum Computer Vision bei der Erkennung von Cyberbedrohungen so hilfreich sein kann.
Zur Veranschaulichung: Hornetsecurity setzt Computer-Vision-Methoden in seinen Phishing-Erkennungsdiensten wie ATP Secure Links ein, um visuelle Muster in Phishing-Versuchen zu identifizieren.
In den kommenden Artikeln werden wir uns also darauf konzentrieren, wie diese Methoden funktionieren, und verschiedene Techniken und Algorithmen der Computer Vision vorstellen, die für diesen Zweck genutzt und kombiniert werden können.
Heutzutage sind E-Mails und Links die hauptsächlichen Einfallstore für Cyberbedrohungen.
- E-Mails sind für die Unternehmenskommunikation unverzichtbar – sei es für den internen Austausch im Team oder die externe Kommunikation mit Kunden und Partnern.
- Links werden ebenfalls häufig geteilt, sowohl per E-Mail als auch über andere Messaging-Kanäle, wie z. B. Unternehmens-Kollaborationstools (Teams, Slack) oder Messaging-Dienste wie WhatsApp und WeChat.
Die Darstellung von E-Mails oder verlinkten Webseiten erfolgt für den Endnutzer stets grafisch – entweder durch die E-Mail-Software oder den Webbrowser. Die Rendering Engine der E-Mail-Software bzw. des Webbrowsers analysiert zunächst das HTML-Dokument, lädt die erforderlichen Ressourcen (Bilder, CSS-, JS-Dateien etc.) und wandelt diese in eine visuelle Darstellung auf dem Endgerät um. Der Endnutzer sieht somit nicht den Quellcode des HTML-Dokuments, sondern die durch die Software generierte visuelle Darstellung.
Webtechnologien (HTML, CSS, JS) sind im Laufe der Zeit immer ausgefeilter geworden. Dies hat Cyberkriminellen ermöglicht, Techniken zu entwickeln, mit denen sie Sicherheitsmaßnahmen wie E-Mail-Filter und Webscanner umgehen können, die auf Inhaltsanalysen anstelle der visuellen Darstellung basieren. Diese Techniken können genutzt werden, um bösartige Inhalte oder Hinweise auf einen Angriff zu verbergen oder um die Analysen der Sicherheitsmechanismen gezielt zu stören.
Techniken, die Angreifer zur Umgehung traditioneller Filter einsetzen
Unter den zahlreichen Techniken, die von Cyberkriminellen eingesetzt werden, konzentrieren wir uns auf zwei besonders raffinierte Ansätze, die für traditionelle Sicherheitsmaßnahmen eine erhebliche Herausforderung darstellen.
Phishing mit QR-Code
Der folgende Screenshot einer E-Mail zeigt einen Phishing-Versuch auf Basis eines QR-Codes, der vorgibt, von DHL zu stammen. Der QR-Code wurde aus Sicherheitsgründen teilweise unkenntlich gemacht.

Der Einsatz von QR-Codes für Phishing-Angriffe – auch als „Quishing“ bekannt – ist mittlerweile gängige Praxis, da Endnutzer es gewohnt sind, diese Codes mit ihrem Smartphone zu scannen. Für Angreifer sind QR-Codes ein äußerst effizienter Weg, bestehende Sicherheitsmaßnahmen zu umgehen, da das Extrahieren des zugrunde liegenden Links den Einsatz kostenintensiver Computer-Vision-Techniken erfordert.
QR-Codes sind in der Regel Bilder, die entweder als Anhang der E-Mail beigefügt oder in einem HTML-Bild-Tag referenziert werden. Im vorliegenden Beispiel ist dies jedoch nicht der Fall. Hier entsteht der QR-Code erst durch das Rendering der E-Mail: Im HTML-Quellcode wird der QR-Code durch die Verkettung blockartiger Zeichen in einer Tabellenstruktur gebildet. Eine Vergrößerung des QR-Codes zeigt die Anordnung dieser Zeichen, die im E-Mail-Client sogar einzeln ausgewählt werden können, wie im folgenden Beispiel dargestellt.

Aus Verteidigungsperspektive erfordert das Extrahieren des bösartigen Links eine vollständige Rendering-Analyse der E-Mail, anstatt lediglich die angehängten oder im Quellcode referenzierten Bilder zu verarbeiten. Diese Technik, HTML-Tabellen zu nutzen, um visuelle Inhalte dynamisch zu erzeugen, wurde ebenfalls eingesetzt, um Marken zu imitieren. Dabei werden die Pixel eines Logos mithilfe farbiger Blöcke generiert. Diese Methode wurde bereits genutzt, um Unternehmen wie Microsoft und Chase zu imitieren, wie in den folgenden Beispielen gezeigt.
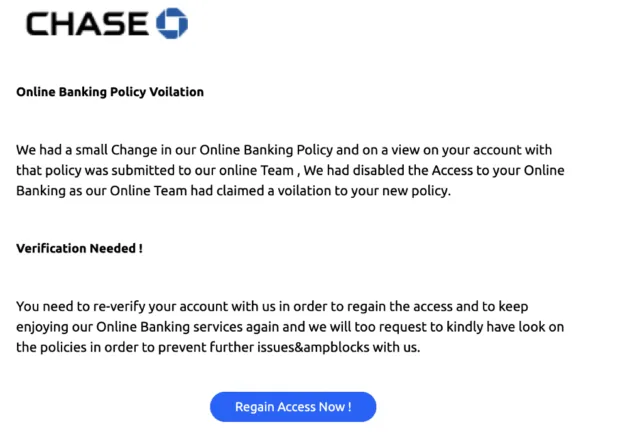
Wenn wir das Chase-Logo vergrößern, sehen wir, dass es aus einer Anordnung blauer Farbblöcke innerhalb einer HTML-Tabelle besteht.

ZeroFont-Phishing
Eine weitere Technik, um bösartige Elemente zu verbergen und Sicherheitsfilter zu umgehen, ist als „ZeroFont“-Technik bekannt. Die ZeroFont-Technik gehört zu einer größeren Familie von Methoden, die Funktionen von HTML und CSS nutzen, um Text einzufügen, der für den Endnutzer nicht sichtbar ist. Dabei kann es sich um Text handeln, dessen Farbe identisch oder ähnlich zur Hintergrundfarbe ist, oder um das Verbergen eines Elements durch die CSS-Eigenschaft “visibility”.
Und wie der Name schon sagt, basiert die ZeroFont-Technik darauf, Text einzufügen, dessen Schriftgröße auf null gesetzt ist, sodass dieser für den Endnutzer nicht gerendert und sichtbar ist. Da HTML und CSS komplex sind, gibt es zahlreiche Möglichkeiten, dies zu erreichen. Die einfachste Methode besteht darin, die Schriftgröße auf null Pixel zu setzen. Da defensive Sicherheitsmechanismen dies jedoch erkennen können, haben Angreifer zahlreiche Varianten entwickelt, indem sie die Komplexität der CSS-Eigenschaften nutzen (z. B. relative Längeneinheiten, Stile usw.) oder die Schriftgröße auf einen Wert nahe null setzen.
Ein Beispiel dafür ist ein Betrugsversuch, bei der die Marke Geek Squad imitiert wird – ein technischer Support-Dienst von Best Buy. Ziel ist es, Nutzer zum Anruf einer betrügerischen Service-Nummer zu bewegen.

Eine Analyse des HTML-Quellcodes zeigt, dass die betrügerische Telefonnummer auf eine komplexe Weise verschleiert wurde, wie im Folgenden dargestellt. HTML-Span-Elemente mit einer Schriftgröße von null (siehe style=“font-size:0vw”) wurden zwischen den Zahlen- und Bindestrichsequenzen eingefügt (‚88‘, ‚8-‘, ‚72‘, ‚9-‘, ‚12‘ und ‚52‘). Dadurch wird es für traditionelle E-Mail-Filter äußerst schwierig, die Telefonnummer zu extrahieren.

Wie kann Computer Vision nützlich sein?
Diese Techniken verdeutlichen die Notwendigkeit, Computer Vision einzusetzen, um das Signal korrekt aus dem Rauschen zu extrahieren und eine E-Mail oder Webseite so zu analysieren, wie ein Mensch es tun würde. Dies ist jedoch mit Herausforderungen verbunden, da Computer Vision ressourcenintensiv ist. Zudem ist es notwendig, die E-Mail oder Webseite zuvor zu rendern, ein Vorgang, der mehrere Sekunden in Anspruch nehmen kann, wenn Ressourcen wie Bilder, CSS- oder JS-Dateien aus dem Internet abgerufen werden müssen, um eine korrekte und originalgetreue grafische Darstellung zu gewährleisten.
E-Mail-Rendering zur Analyse verdächtiger E-Mails
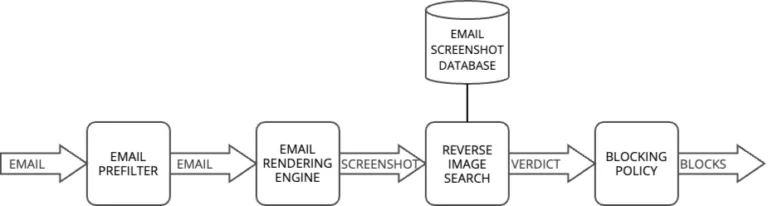
In der Praxis kann eine solche Analyse im E-Mail-Kontext nur auf einer Auswahl des gesamten E-Mail-Verkehrs durchgeführt werden. Dabei sollten ausschließlich die verdächtigsten E-Mails für eine Analyse in Betracht gezogen werden. Ein möglicher Ablauf für diese Pipeline wird im folgenden Diagramm vorgestellt.

- Zunächst wird der E-Mail-Verkehr vorgefiltert, wobei Elemente wie unbekannte Absenderadressen analysiert werden, um verdächtige E-Mails zu identifizieren.
- Wenn eine E-Mail verdächtig erscheint, erfolgt eine grafische Darstellung durch eine Rendering-Engine, wie beispielsweise chromedp.
- Diese Darstellung (Screenshot) wird anschließend von der Computer-Vision-Engine analysiert, die je nach implementierten Funktionen Text mittels OCR (z. B. Telefonnummern im Geek-Squad-Betrug) oder Links aus QR-Codes mit einem Barcode-Scanner (wie im DHL-Phishing-Beispiel) extrahieren kann.
- Die gewonnenen Informationen werden an eine Entscheidungs-Engine übermittelt, die ein Urteil fällt.
- Je nach Ergebnis werden Elemente wie Absender-E-Mail-Adressen, Domains, IP-Adressen oder im Fall eines bösartigen Links die URL und Domain blockiert, um zukünftige Angriffe zu verhindern.
Umgekehrte Bildersuche zur Erkennung bösartiger Inhalte
Ein alternativer Ansatz könnte außerdem darin bestehen, die Computer-Vision-Engine und die Entscheidungs-Engine durch eine Reverse-Image-Search-Komponente zu ersetzen, die mit einer Datenbank von E-Mail-Screenshots gekoppelt ist.
Warum dieser spezielle Ansatz?
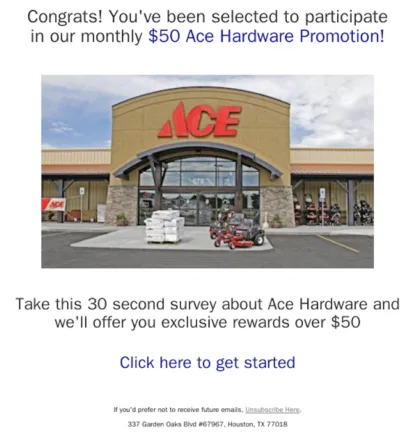
Der Grund dafür ist, dass die Analysten von Hornetsecurity immer wieder mit raffinierten und wiederkehrenden Spam-Kampagnen konfrontiert werden, die bekannte Einzelhandelsmarken wie Costco, Lowes, Walmart und Ace Hardware imitieren. Eine der größten Herausforderungen besteht darin, dass der Inhalt der E-Mails stark variiert – die Spammer kennen alle Tricks, um Rauschen hinzuzufügen und relevante Inhalte zu verschleiern. Gleichzeitig verändert sich die visuelle Darstellung der E-Mails über die Zeit nur geringfügig – jedoch gibt es subtile Anpassungen.
Beispiele variabler Inhalte in einer E-Mail
Zwei Beispiele solcher E-Mails zeigen, wie der Endnutzer dazu verleitet wird, auf einen Spam-Link zu klicken. Obwohl die E-Mails ähnlich sind, weisen sie Unterschiede auf: Der offensichtlichste ist die Änderung der Textfarbe (zuerst rot, dann blau). Darüber hinaus gibt es subtilere Veränderungen, wie die relative Bildgröße und die Abstände zwischen den verschiedenen Blöcken.

Wie man solche Inhalte erkennt
Um diese Art von wiederkehrendem Spam zu erkennen, könnte ein Ansatz darin bestehen, dass Analysten eine Datenbank mit bekannten „Spam“-Screenshots bereitstellen. Jedes Mal, wenn eine verdächtige E-Mail analysiert wird, würde die Reverse-Image-Search-Komponente die Datenbank abfragen, um zu prüfen, ob der Screenshot der E-Mail bereits als „Spam“ bekannt ist. Ist dies der Fall, werden entsprechende Elemente blockiert, um die Kampagne zu stoppen.
Die Reverse-Image-Search-Komponente muss dabei in der Lage sein, eine „unscharfe Suche“ durchzuführen, also kleine Änderungen im Screenshot zu tolerieren. Das gleiche Prinzip kann auch verwendet werden, um andere wiederkehrende bösartige E-Mails wie Phishing zu erkennen. So könnten beispielsweise Varianten einer Phishing-Kampagne entdeckt werden, etwa eine Phishing-E-Mail mit einem abweichenden QR-Code.

Fazit
In den nächsten Artikeln werden wir uns intensiv mit den Algorithmen beschäftigen, die zur Implementierung einer Reverse-Image-Search-Engine verwendet werden können. Dieses Problem – auch bekannt als Duplicate Image Detection oder Near-Duplicate Image Detection – wurde bereits ausführlich von Wissenschaftlern untersucht. Wir werden dabei auf die bestehende Forschungsliteratur Bezug nehmen.

